책소개
최신 딥러닝 기술을 활용한 자연어 처리
기본기부터 실전 심화까지 한 권으로 끝내기
자연어 처리 기초부터 심화까지 파이토치를 활용하여 짜임새 있게 설명한다. 저자가 현업에서 시스템을 구현하며 얻은 경험과 인사이트를 최대한 담았다. 자칫 지루할 수 있는 수학적 이론을 최소화하고 실전에 꼭 필요한 개념을 정리했다. 최신 딥러닝을 활용한 기술뿐만 아니라, 딥러닝 이전의 전통적인 방식도 차근차근 설명하여 왜 지금의 기술이 필요하고, 어떤 부분이 성능 개선을 이끌어냈는지 쉽게 이해할 수 있다. 딥러닝과 머신러닝 관련 개념과 이론의 기본기를 어느 정도 갖춘 독자라면 자연어 처리를 실무에 적용하는 데 필요한 지식을 이 한 권으로 체계적으로 익힐 수 있다.
![[상세이미지]김기현의 자연어 처리 딥러닝 캠프(파이토치 편)_940.jpg](https://www.hanbit.co.kr/data/editor/20190621103809_nlhcpcbe.jpg)
저자소개

목차
0장_ 윈도우 개발 환경 구축
0.1_ 아나콘다 설치
0.2_ 파이토치 설치
0.3_ 깃 설치
1장_ 딥러닝을 활용한 자연어 처리 개요
1.1_ 자연어 처리란 무엇일까?
1.2_ 딥러닝 소개
1.3_ 왜 자연어 처리는 어려울까?
1.4_ 무엇이 한국어 자연어 처리를 더욱 어렵게 만들까?
1.5_ 자연어 처리의 최근 추세
2장_ 기초 수학
2.1_ 확률 변수와 확률 분포
2.2_ 쉬어가기: 몬티 홀 문제
2.3_ 기댓값과 샘플링
2.4_ MLE
2.5_ 정보 이론
2.6_ 쉬어가기: MSE 손실 함수와 확률 분포 함수
2.7_ 마치며
3장_ Hello 파이토치
3.1_ 딥러닝을 시작하기 전에
3.2_ 설치 방법
3.3_ 짧은 튜토리얼
4장_ 전처리
4.1_ 전처리
4.2_ 코퍼스 수집
4.3_ 정제
4.4_ 문장 단위 분절
4.5_ 분절
4.6_ 병렬 코퍼스 정렬
4.7_ 서브워드 분절
4.8_ 분절 복원
4.9_ 토치텍스트
5장_ 유사성과 모호성
5.1_ 단어의 의미
5.2_ 원핫 인코딩
5.3_ 시소러스를 활용한 단어 의미 파악
5.4_ 특징
5.5_ 특징 추출하기: TF-IDF
5.6_ 특징 벡터 만들기
5.7_ 벡터 유사도 구하기
5.8_ 단어 중의성 해소
5.9_ 선택 선호도
5.10_ 마치며
6장_ 단어 임베딩
6.1_ 들어가며
6.2_ 차원 축소
6.3_ 흔한 오해 1
6.4_ word2vec
6.5_ GloVe
6.6_ word2vec 예제
6.7_ 마치며
7장_ 시퀀스 모델링
7.1_ 들어가며
7.2_ 순환 신경망
7.3_ LSTM
7.4_ GRU
7.5_ 그래디언트 클리핑
7.6_ 마치며
8장_ 텍스트 분류
8.1_ 들어가며
8.2_ 나이브 베이즈 활용하기
8.3_ 흔한 오해 2
8.4_ RNN 활용하기
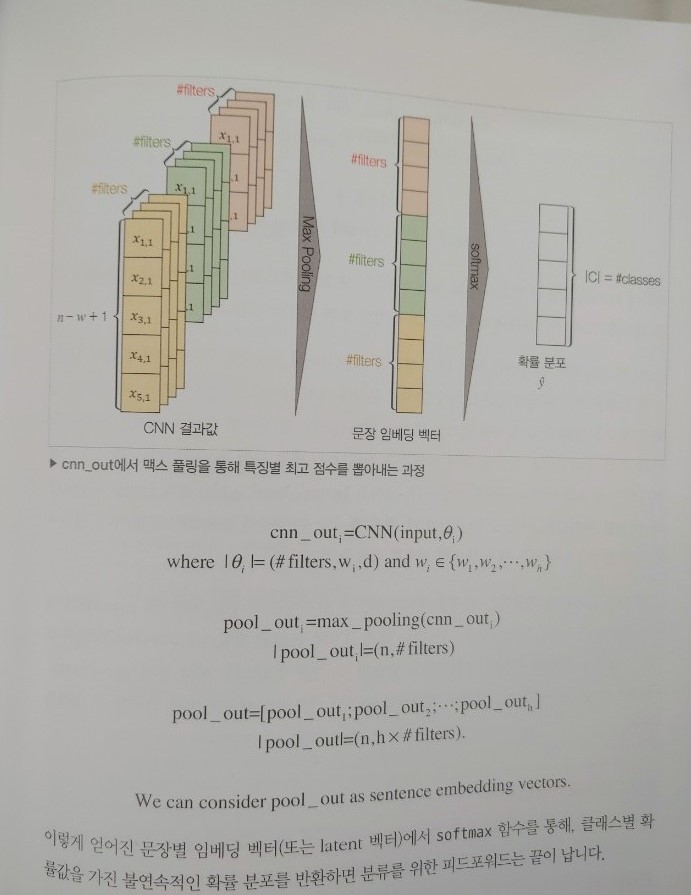
8.5_ CNN 활용하기
8.6_ 쉬어가기: 멀티 레이블 분류
8.7_ 마치며
9장_ 언어 모델링
9.1_ 들어가며
9.2_ n-gram
9.3_ 언어 모델의 평가 방법
9.4_ SRILM을 활용하여 n-gram 실습하기
9.5_ NNLM
9.6_ 언어 모델의 활용
9.7_ 마치며
10장_ 신경망 기계번역
10.1_ 기계번역
10.2_ seq2seq
10.3_ 어텐션
10.4_ input feeding
10.5_ 자기회귀 속성과 Teacher forcing 훈련 방법
10.6_ 탐색(추론)
10.7_ 성능 평가
10.8_ 마치며
11장_ 신경망 기계번역 심화 주제
11.1_ 다국어 신경망 번역
11.2_ 단일 언어 코퍼스 활용하기
11.3_ 트랜스포머
11.4_ 마치며
12장_ 강화학습을 활용한 자연어 생성
12.1_ 들어가며
12.2_ 강화학습 기초
12.3_ 정책 기반 강화학습
12.4_ 자연어 생성에 강화학습 적용하기
12.5_ 강화학습을 활용한 지도학습
12.6_ 강화학습을 활용한 비지도학습
12.7_ 마치며
13장_ 듀얼리티 활용
13.1_ 들어가며
13.2_ 듀얼리티를 활용한 지도학습
13.3_ 듀얼리티를 활용한 비지도학습
13.4_ 쉬어가기: Back-translation 재해석하기
13.5_ 마치며
14장_ NMT 시스템 구축
14.1_ 파이프라인
14.2_ 구글의 NMT
14.3_ 에든버러 대학교의 NMT
14.4_ MS의 NMT
15장_ 전이학습
15.1_ 전이학습이란
15.2_ 기존의 사전 훈련 방식
15.3_ ELMo
15.4_ BERT
15.5_ OpenAI의 GPT-2
15.6_ 마치며
출판사리뷰
딥러닝 기반 자연어 처리의 기본적인 내용부터 최신 트렌드까지 한데 아울러 소개합니다. 모델링 이슈뿐만 아니라 언어 처리에서 고려해야 하는 각종 요소를 설명합니다. 언어 관련 인공지능 서비스를 시작하는 분들에게 좋은 지침서가 될 것입니다.
김강일_ 광주과학기술원 전기전자컴퓨터공학부 교수
복잡한 수식과 정교한 이론을 소개하는 책으로 머신러닝을 시작했다가 중도 포기하신 분, 또는 머신러닝을 말로만 쉽게 설명하는 책을 몇 권 읽었지만 남는 것이 없다고 느끼신 분께 이 책을 추천합니다. 워드 임베딩, 언어 모델링, 기계번역 등 자연어 처리 분야의 주요 주제에 관한 배경지식과 수식을 잘 설명합니다. 제시된 파이썬 샘플 코드를 통해 관련 내용을 직접 구현해보며 이해를 높일 수 있습니다. 이 한 권으로 자연어 처리를 모두 이해할 수는 없겠지만, 앞으로의 학습 방향 설정에 좋은 나침반 역할을 해줄 것입니다.
노형석_ 네이버 챗봇 모델팀 머신러닝 엔지니어
현재 의료 분야를 포함한 다양한 산업군에서 인공지능을 기반으로 한 자연어 처리를 활발하게 사용하고 있습니다. 일상에서 쉽게 발견할 수 있는 형태로는 번역이나 챗봇 등으로, 인공지능 기반의 자연어 처리는 이미 우리 삶에 깊게 침투해 있습니다. 이 책은 평소 인공지능 기술에 관심이 많았던 사람이라면 누구나 자연어 처리 기술을 개발할 수 있도록 쓰였습니다. 딥러닝 기술을 위한 기초 지식부터 자연어 처리의 핵심적인 응용 방법에 이르기까지 폭넓은 내용을 심도 있게 다룹니다. 나아가 자연어의 특수성으로 인해 구현 과정에서 맞닥뜨리는 다양한 문제를 정의하고 이에 대한 해결책을 제시합니다. 특히 자연어 처리가 아닌 타 분야에서 인공지능을 경험한 사람이라면 자연어 처리 구현을 시도하기에 앞서 이 책을 읽어보기를 추천합니다.
박승균_ Lunit 공동창업자, Head of Chest Radiology, UNIST 겸임교수
정치, 경제, 산업, 사회 면에서 총체적 변화가 이루어지는 4차 산업혁명 시대의 핵심 기술인 AI에 관한 저자의 경험과 노하우가 잘 담겨 있습니다. 기존 NLP 분야 책은 언어 구조가 한국어와 다른 영문 예제를 바탕으로 설명한 번역서였습니다. 그런데 이 책에는 한국어 예제와 설명, 실전에서 바로 활용할 수 있는 코드 사례가 함께 실려있으며, 무엇보다도 실제 산업 현장에서 다양한 AI 문제를 해결하려는 저자의 고민과 노력이 담겨 있습니다. 이 책의 출간은 AI 분야에 종사하는 많은 독자에게 참으로 반가운 소식이 될 것입니다.
심탁길_ CJ올리브네트웍스 빅데이터&마케팅본부 상무
딥러닝 기반의 자연어 처리를 기초부터 심화 내용까지 충실히 설명합니다. 단순히 최신 알고리즘의 이론적인 나열에 그치지 않고, 저자의 풍부한 경험과 지식을 바탕으로 조화롭게 총체적으로 학습할 수 있도록 접근합니다. 번역서를 제외하고는 아직 자연어 처리에 관한 국내 도서가 드문 현실에서 가뭄의 단비와 같은 책입니다.
윤승_ 한국전자통신연구원 음성지능연구그룹 선임연구원
김기현 저자는 패스트캠퍼스에서 자연어 처리 초급부터 고급 과정까지 강의를 진행하는 해당 주제 대표 강사입니다. 이 강의에서는 현업에서 번역기를 개발하여 실제 상용화한 경험을 바탕으로 수강생 여러분께 꼭 필요한 이론과 실습, 그리고 현업에서의 노하우까지 친절하게 알려줍니다. 매 기수 명쾌하고 훌륭한 설명으로 강의 만족도는 만점에 가깝습니다.
이 책은 그간의 강의를 생생하게 녹여낸 자연어 처리 분야의 필독서입니다. 단순히 내용을 열거하고 정리한 책이 아닌, 독학으로는 오래 걸리고 이해하기 어려운 NLP에 대한 전반적인 내용과 파이토치를 활용한 코드 구현, 외국 강의만으로는 알기 어려운 한글 처리에 대한 인사이트까지 자세하게 설명합니다. 패스트캠퍼스에서 벌써 1년 넘게 자연어 처리 강의를 진행 중인 저자의 노하우가 담긴 체계적인 구성은 독자 여러분에게 많은 도움을 줄 것이라 확신합니다.
이샘_ 패스트캠퍼스 콘텐츠기획개발사업부 시니어 프로덕트 매니저
책을 통해 얻을 수 있는 중요한 가치는 체계적인 지식과 더불어 저자의 직관과 경험에서 우러나오는 노하우라고 생각합니다. 이 책은 자연어 처리 전문가이자, 다년간의 실무 개발 경험과 강의를 통한 지식 전달 능력을 인정받은 실력 있는 저자의 지식과 노하우가 고스란히 담겨 있습니다. 자연어 처리의 각 단계를 잘 설명하며, 샘플 코드에는 단계별로 직면하는 문제들을 해결하는 저자의 경험이 그대로 녹아들어 있습니다. 책을 읽으며 코드를 따라가다 보면 어느새 자연어 처리와 딥러닝의 응용 역량을 함께 갖출 수 있을 것입니다. 좋은 기술 서적을 만들어준 저자의 노고에 감사하며 기쁘게 추천합니다.
장언동_ 이베이코리아 AI 플랫폼 팀장
한 달이 멀다 하고 새로운 알고리즘이 나오는 자연어 처리 분야에서 최신 기술을 최대한 집어넣으려는 의지가 강하게 엿보이는 책입니다. 이론뿐만 아니라 실제 서비스가 어떤 식으로 이루어지는지 엿볼 수 있는 것도 이 책을 읽는 큰 즐거움 중 하나입니다.
최성준_서울대학교 공학박사
추천도서
오탈자 등록