책소개
함정과 딜레마를 극복하는 올바른 시맨틱 가이드
빅데이터와 인공지능 열풍 시대에 데이터는 금광으로 여겨진다. 그리고 수많은 데이터 실무자와 거대 기업은 그 속에서 가치를 얻으려 노력한다. 하지만 데이터는 있지만 금이 없을 때도 있고 기업에서 사용할 만한 양의 금이 들어 있지 않을 때도 있다. 데이터와 금이 모두 있지만 정작 금 추출에 필요한 설비나 기술이 아직 사용 할 만큼 충분히 발달하지 않은 때도 있다.
이 책은 시맨틱 데이터 모형화를 통해 데이터를 유용하게 다루고 그 속에서 가치를 높이는 방법을 제시한다. 또한 모형화 과정에서 직면할 ‘함정’과 ‘딜레마’를 통해 데이터 실무자가 알아야 할 데이터 모형화의 ‘좋은 사례’와 ‘나쁜 사례’를 학습한다. 저자의 실제 사례를 바탕으로 한 경험을 간접적으로 익히며 데이터를 보고 이해하는 시야를 넓혀보자.
저자소개

목차
[PART I 기초]
CHAPTER 1 시맨틱 격차에 유념하기
_1.1 시맨틱 데이터 모형화의 의미
_1.2 시맨틱 데이터 모형을 개발해서 사용하는 이유
_1.3 잘못된 시맨틱 모형화
_1.4 함정 피하기
_1.5 딜레마 깨기
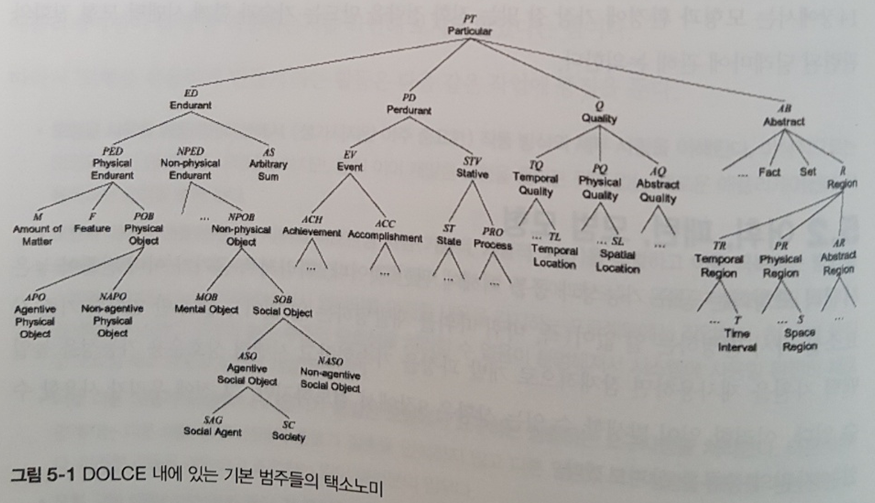
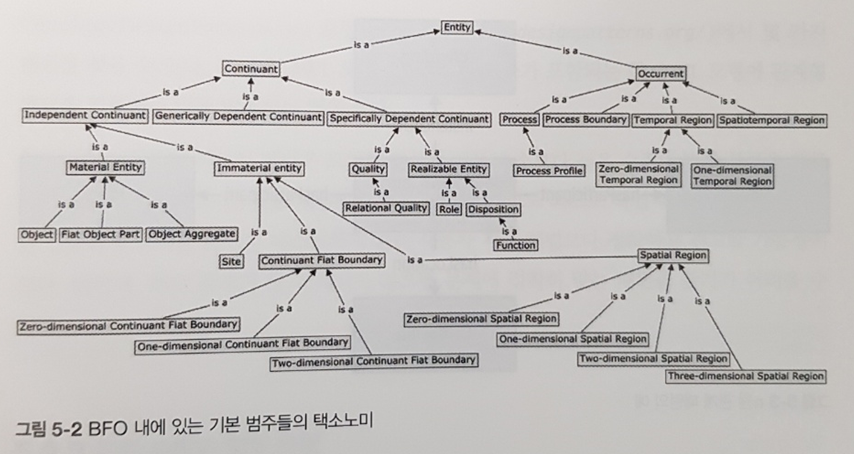
CHAPTER 2 시맨틱 모형화 요소
_2.1 일반 요소
_2.2 공통 요소와 표준화된 요소
_2.3 요약
CHAPTER 3 시맨틱 현상과 언어적 현상
_3.1 모호성
_3.2 불확실성
_3.3 애매성
_3.4 경직성, 동일성, 단일성, 의존성
_3.5 대칭성, 반전성, 전이성
_3.6 닫힌 세계 가정과 열린 세계 가정
_3.7 의미 변화
_3.8 요약
CHAPTER 4 시맨틱 모형 품질
_4.1 의미 정확성
_4.2 완비성
_4.3 무모순성
_4.4 간결성
_4.5 시의성
_4.6 관련성
_4.7 이해성
_4.8 신뢰성
_4.9 가용성, 융통성, 성능
_4.10 요약
CHAPTER 5 시맨틱 모형 개발
_5.1 개발 활동
_5.2 어휘, 패턴, 모범 모형
_5.3 시맨틱 모형 마이닝
_5.4 요약
[PART II 함정]
CHAPTER 6 나쁜 설명
_6.1 나쁜 이름 부여
_6.2 정의를 생략하거나 나쁜 정의를 부여하기
_6.3 애매성 무시
_6.4 편견과 가정을 문서화하지 않음
_6.5 요약
CHAPTER 7 잘못된 의미
_7.1 나쁜 동일성
_7.2 나쁜 하위 클래스
_7.3 나쁜 공리와 나쁜 규칙
_7.4 요약
CHAPTER 8 잘못된 모형 규격 및 지식 습득
_8.1 잘못된 것을 구축하는 일
_8.2 나쁜 지식 습득
_8.3 규격 및 지식 습득 이야기
_8.4 요약
CHAPTER 9 나쁜 품질 관리
_9.1 품질을 상반 관계로 취급하지 않음
_9.2 품질을 위험과 이익에 연결하지 않음
_9.3 올바른 지표를 사용하지 않음
_9.4 요약
CHAPTER 10 잘못된 애플리케이션
_10.1 잘못된 엔터티 해소
_10.2 잘못된 시맨틱 관련성
_10.3 요약
CHAPTER 11 나쁜 전략과 나쁜 조직
_11.1 나쁜 전략
_11.2 나쁜 조직
_11.3 요약
[PART III 딜레마]
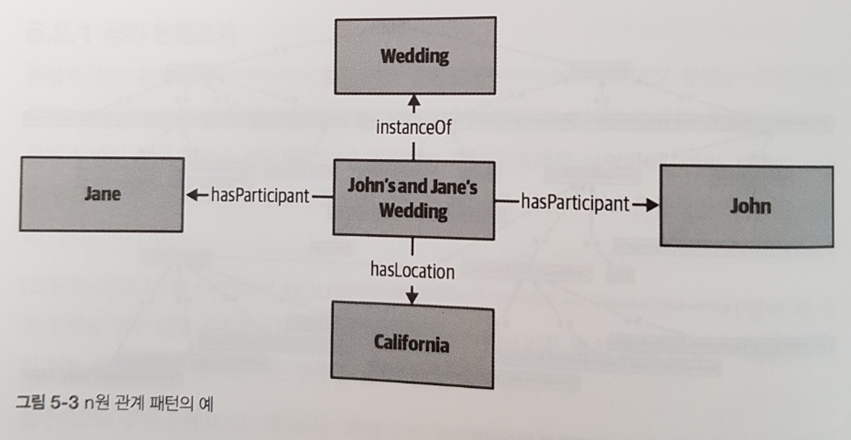
CHAPTER 12 표현성 딜레마
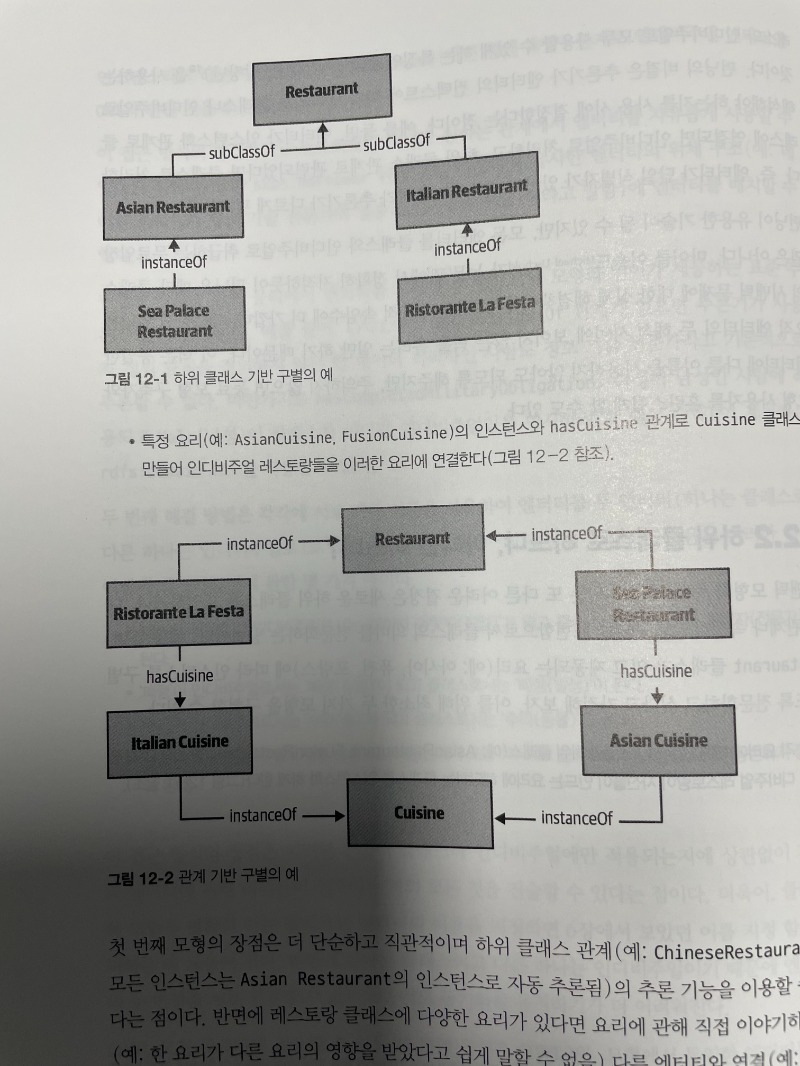
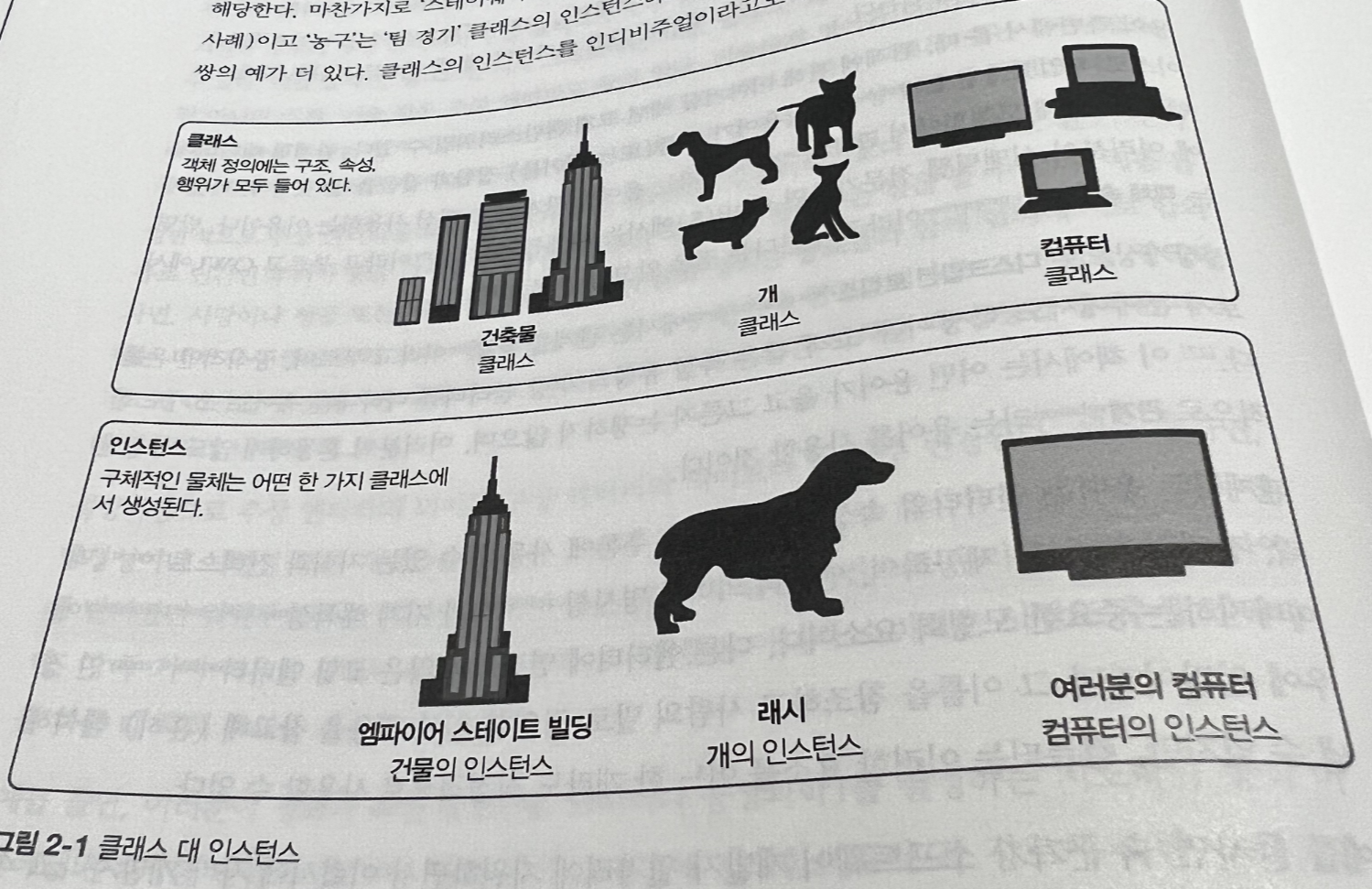
_12.1 클래스인가 아니면 인디비주얼인가?
_12.2 하위 클래스로 하느냐, 아니면 마느냐?
_12.3 속성이냐, 아니면 관계냐?
_12.4 퍼지화하느냐, 아니면 마느냐?
_12.5 요약
CHAPTER 13 표현성과 내용 간의 딜레마
_13.1 어떤 어휘화가 있어야 하는가?
_13.2 얼마나 세분화될까?
_13.3 얼마나 일반적이어야 하는가?
_13.4 얼마나 부정적이어야 하는가?
_13.5 얼마나 많은 진리를 처리해야 하는가?
_13.6 어떻게 연결되어야 하는가?
_13.7 요약
CHAPTER 14 진화와 거버넌스 딜레마
_14.1 모형 진화
_14.2 모형 거버넌스
_14.3 요약
CHAPTER 15 미래 전망
_15.1 지도는 영토가 아니다
_15.2 낙천주의자로 살면서도 순진해빠지지 않기
_15.3 좁은 시야에서 벗어나기
_15.4 산만한 토론 피하기
_15.5 해를 끼치지 않기
_15.6 시맨틱 격차 해소
출판사리뷰
시맨틱 데이터 모형을 사용하는 이유
구글은 2012년에 <우리가 만든 지식 그래프로 문자열뿐만 아니라 사물도 검색할 수 있었다>고 발표했고, 가트너는 2018년에 신흥 기술의 하이프 사이클에 지식 그래프를 포함했다고 발표했다. 현재는 구글 외에도 아마존, 링크드인, 톰슨 로이터, BBC, IBM 등 다양한 조직이 시맨틱 데이터 모형을 개발해 자신들의 제품이나 서비스에 접목하고 있다.
이런 회사들이 시맨틱 데이터 모형에 투자하려는 한 가지 이유는 인공지능의 기능, 데이터 과학 애플리케이션의 기능, 서비스의 기능을 높이기 위해서다. 이처럼 시맨틱 응용 기능들 또한 머신러닝 기술과 통계 기술에 기반을 두기는 하지만, 몇 가지 작업을 더 거쳐야 명료한 기호적 지식에 접근할 수 있게 되고 유익해진다.
예를 들어, 인기 퀴즈 쇼인 <제퍼디!>에서 경연을 펼친 왓슨은 질문의 답을 찾을 때 정형화되지 않은 정보에 의존해서 대부분의 증거 분석 작업을 했지만, 일부 구성 부분에서는 지식 기반 방법과 온톨로지 방식을 사용해 특정 지식과 추론 문제를 해결했다. 이렇듯 시맨틱 모형은 일반적으로 이종 데이터나 사일로 데이터의 의미를 표준화하거나 정렬하는 일, 컨텍스트(상황, 맥락,장면적 컨텍스트)를 제공하는 일, 분석 등의 용도로 더 잘 검색할 수 있게 하는 일, 상호운용이 되도록 하는 일, 활용할 수 있게 만드는 일 등을 처리한다.
오탈자 등록