책소개
캐글 우승자들의 머신러닝 우승 비법이자 현존하는 가장 우월한 머신러닝 모델 XGBoost
이 책은 기본적인 머신러닝과 판다스부터 사용자 정의 변환기, 파이프라인과 희소 행렬로 새로운 데이터의 예측을 만드는 강력한 XGBoost 모델 튜닝까지 모두 다룹니다. 또한 XGBoost의 탄생 배경과 XGBoost를 특별하게 만드는 수학적 이론과 기술, 물리학자와 천문학자가 우주를 연구하는 사례 연구까지 다양한 XGBoost의 흥미로운 이야기와 캐글 마스터들의 우승 비법까지 소개합니다. 마지막으로 더 확실한 이해를 위해 원서에는 없는 친절하고 상세한 역자 노트와 다른 그레이디언트 부스팅 라이브러리를 배울 수 있는 한국어판만의 부록을 추가하여 내용을 더욱 가득 채웠습니다. 이 책 한 권이면 복잡한 XGBoost 개념을 완벽하게 이해하고 제품을 위한 머신러닝을 구축해볼 수 있게 됩니다. 그레이디언트 부스팅을 현업에 적용해보고 싶은 머신러닝 엔지니어나 캐글 대회를 준비하고 있는 캐글 도전자에게 훌륭한 안내서가 되어줄 것입니다.

저자소개


목차
CHAPTER 0 코딩 환경 설정
0.1 아나콘다
0.2 주피터 노트북 사용하기
0.3 XGBoost
0.4 버전
PART 1 배깅과 부스팅
CHAPTER 1 머신러닝 개요
1.1 XGBoost 소개
1.2 데이터 랭글링
1.3 회귀 모델 만들기
1.4 분류 모델 만들기
1.5 마치며
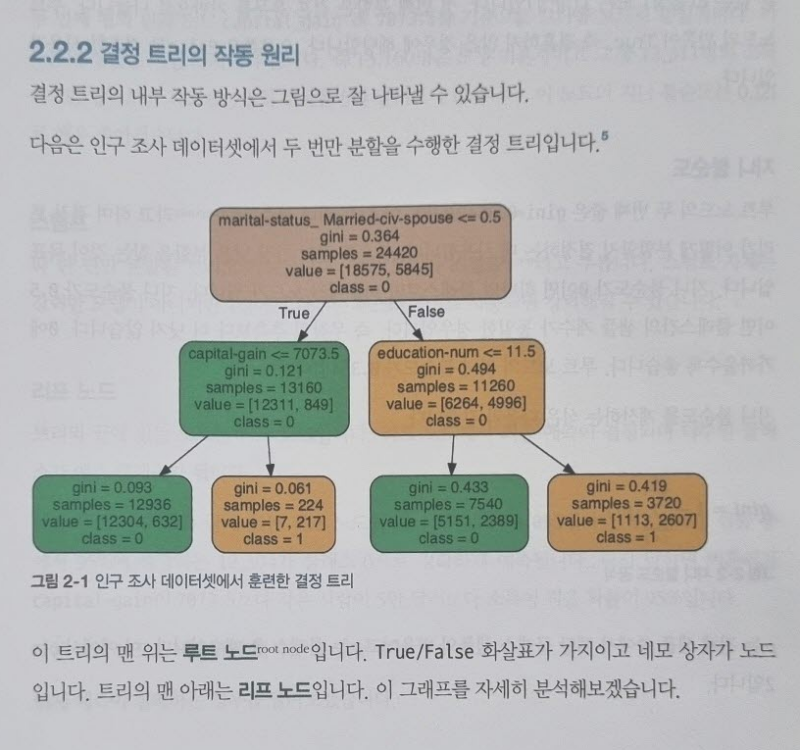
CHAPTER 2 결정 트리
2.1 결정 트리 소개
2.2 결정 트리 알고리즘
2.3 분산과 편향
2.4 결정 트리 하이퍼파라미터 튜닝
2.5 심장 질환 예측하기 - 사례 연구
2.6 마치며
CHAPTER 3 배깅과 랜덤 포레스트
3.1 배깅 앙상블
3.2 랜덤 포레스트 살펴보기
3.3 랜덤 포레스트 매개변수
3.4 랜덤 포레스트 성능 높이기 – 사례 연구
3.5 마치며
CHAPTER 4 그레이디언트 부스팅에서 XGBoost까지
4.1 배깅에서 부스팅까지
4.2 그레이디언트 부스팅 작동 방식
4.3 그레이디언트 부스팅 매개변수 튜닝
4.4 빅 데이터 다루기 - 그레이디언트 부스팅 vs XGBoost
4.5 마치며
PART 2 XGBoost
CHAPTER 5 XGBoost 소개
5.1 XGBoost 구조
5.2 XGBoost 파라미터 최적화
5.3 XGBoost 모델 만들기
5.4 힉스 보손 찾기 – 사례 연구
5.5 마치며
CHAPTER 6 XGBoost 하이퍼파라미터
6.1 데이터와 기준 모델 준비
6.2 XGBoost 하이퍼파라미터 튜닝
6.3 조기 종료 적용
6.4 하이퍼파라미터 결합
6.5 하이퍼파라미터 조정
6.6 마치며
CHAPTER 7 XGBoost로 외계 행성 찾기
7.1 외계 행성 찾기
7.2 오차 행렬 분석하기
7.3 불균형 데이터 리샘플링
7.4 XGBClassifier 튜닝
7.5 마치며
PART 3 고급 XGBoost
CHAPTER 8 XGBoost 기본 학습기
8.1 여러 가지 기본 학습기
8.2 gblinear 적용하기
8.3 dart 비교하기
8.4 XGBoost 랜덤 포레스트
8.5 마치며
CHAPTER 9 캐글 마스터에게 배우기
9.1 캐글 대회 둘러보기
9.2 특성 공학
9.3 상관관계가 낮은 앙상블 만들기
9.4 스태킹
9.5 마치며
CHAPTER 10 XGBoost 모델 배포
10.1 혼합 데이터 인코딩
10.2 사용자 정의 사이킷런 변환기
10.3 XGBoost 모델 만들기
10.4 머신러닝 파이프라인 구성하기
출판사리뷰
데이터 과학 전문가를 위한 XGBoost와 사이킷런 활용법
XGBoost는 빠르고 효율적으로 수십억 개의 데이터 포인트에 적용하기 위한 그레이디언트 부스팅 프레임워크로, 업계에서 입증된 오픈 소스 소프트웨어 라이브러리입니다. 이 책은 그레이디언트 부스팅에 대한 이론을 설명하기 전에 사이킷런으로 머신러닝과 XGBoost를 소개합니다. 결정 트리를 다루고 머신러닝 관점에서 배깅을 분석하며 XGBoost까지 확장되는 하이퍼파라미터를 배우겠습니다. 밑바닥부터 그레이디언트 부스팅 모델을 구축해보고 그레이디언트 부스팅을 빅 데이터로 확장하면서 속도의 중요성을 설명합니다. 그리고 속도 향상 및 수학적인 이론에 초점을 두고 XGBoost의 세부 사항을 알아봅니다. 자세한 사례 연구를 이용하여 사이킷런 API와 원본 파이썬 API 방식으로 XGBoost 분류 모델과 회귀 모델을 만들고 튜닝하는 방법을 연습합니다. 또한, XGBoost 하이퍼파라미터를 활용하여 성능 개선, 누락된 값 수정 및 불균형 데이터 세트 적용, 그리고 다른 기본 학습기를 튜닝합니다. 마지막으로 상관관계가 낮은 앙상블과 스태킹 모델을 만들어보고, 모델 배포를 위해 희소 행렬과 사용자 정의 변환기, 파이프라인과 같은 고급 XGBoost 기술을 적용합니다.
주요 내용
오탈자 등록