책소개
80여 가지 AWS AI & ML 서비스로 구현하는 데이터 과학 프로젝트 실전 가이드
이 책은 AWS에서 제공하는 AI와 ML 기능을 활용하여 데이터 과학 프로젝트를 구축하고 배포하는 방법을 다룬 실전 지침서다. 아마존 EC2, 아마존 EBS, 아마존 다이나모DB, AWS 람다, AWS IAM을 비롯한 다양한 AWS 서비스를 사용하여 데이터 수집 및 처리, 머신러닝, 보안을 다룬다. 또한 AWS에서 데이터 과학 프로젝트의 비용을 절감하고 성능을 향상시키는 팁도 소개한다. 이 책을 따라 모든 학습을 마치고 나면 머신러닝 모델의 성능을 향상하기 위한 기술과 방법을 이해하고, AWS를 효과적으로 활용하여 머신러닝 모델을 구축하고 배포할 수 있게 될 것이다.

저자소개

목차
CHAPTER 1 AWS 기반 데이터 과학 소개
1.1 클라우드 컴퓨팅의 장점
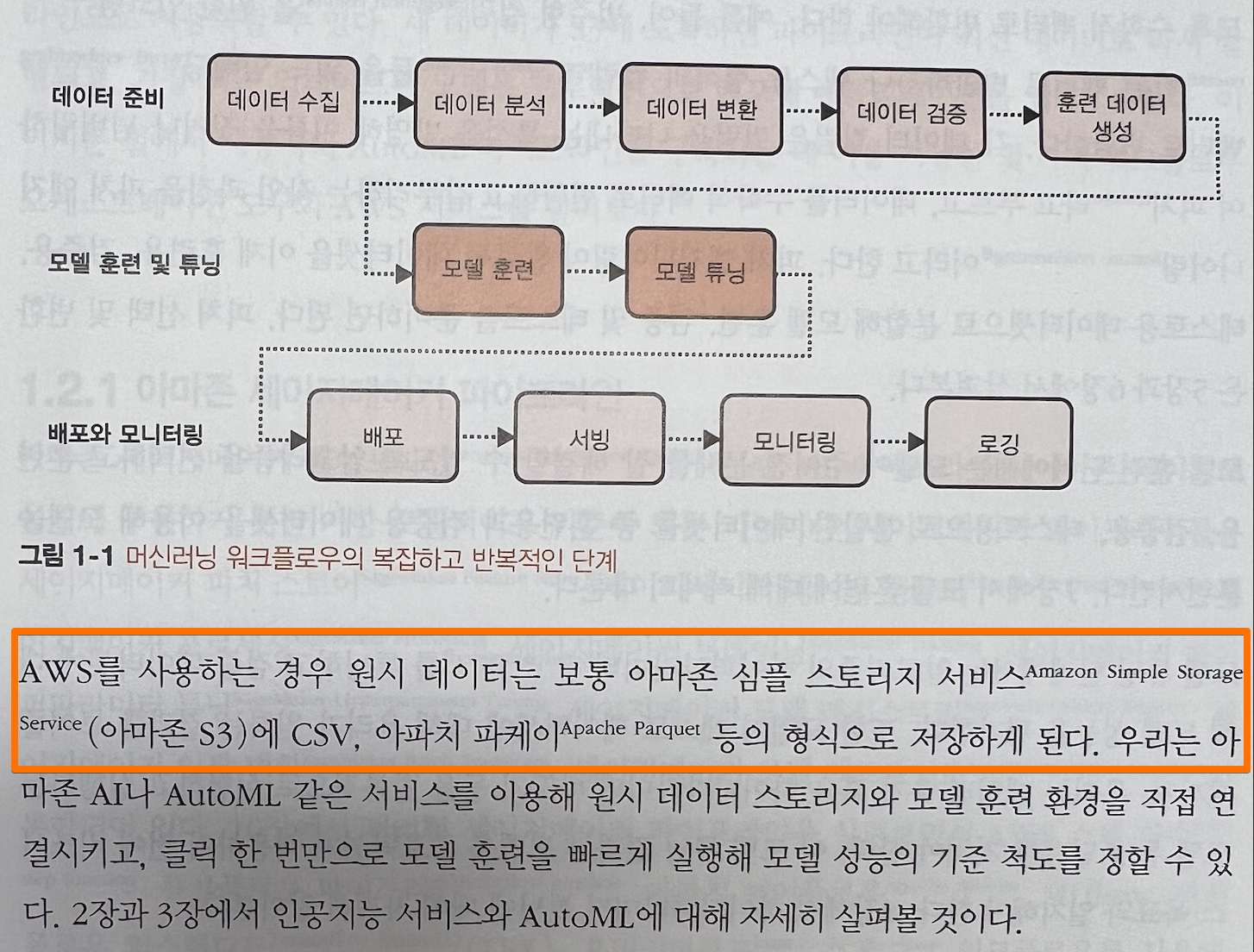
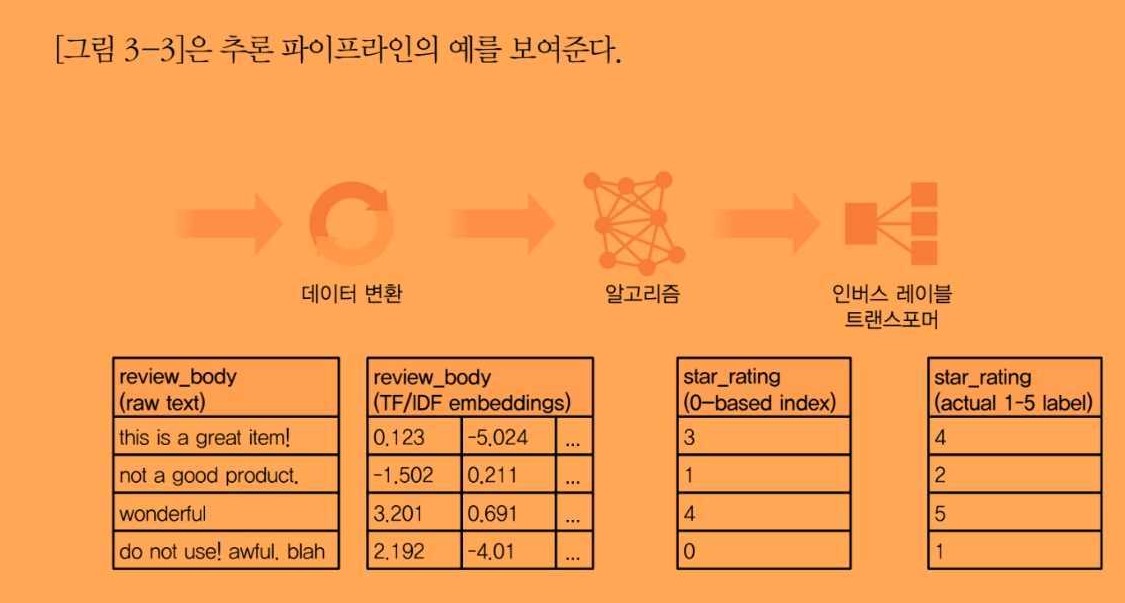
1.2 데이터 과학 파이프라인 및 워크플로우
1.3 MLOps 모범 사례
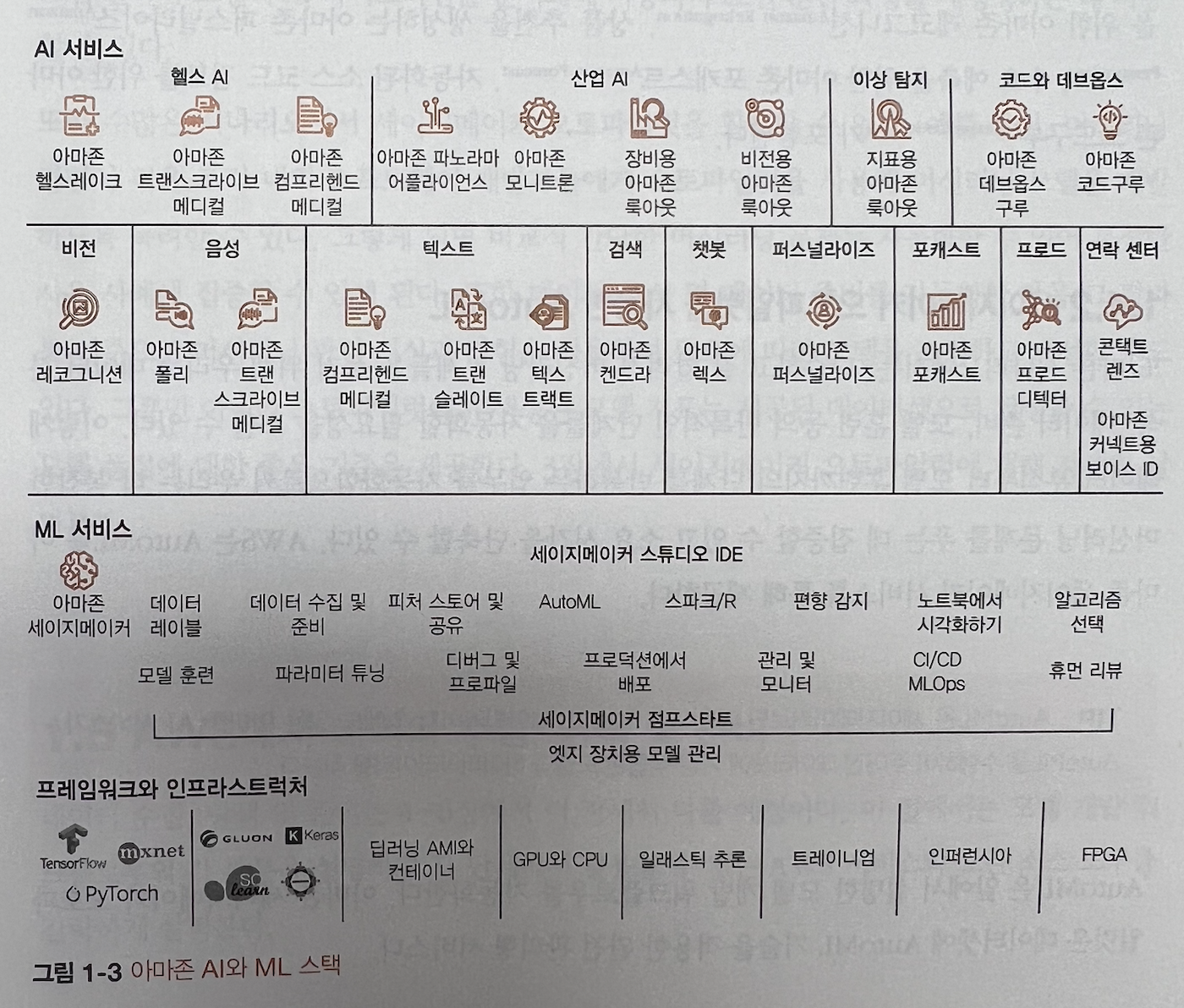
1.4 아마존 세이지메이커를 사용한 아마존 AI와 AutoML
1.5 AWS에서 데이터 수집, 탐색 및 준비
1.6 아마존 세이지메이커를 사용한 모델 훈련 및 튜닝
1.7 아마존 세이지메이커와 AWS 람다 함수를 사용한 모델 배포
1.8 AWS 스트리밍 데이터 분석 및 머신러닝
1.9 AWS 인프라 및 맞춤형 하드웨어
1.10 태그, 예산, 알림으로 비용 절감하기
1.11 마치며
CHAPTER 2 데이터 과학의 모범 사례
2.1 모든 산업에 걸친 혁신
2.2 개인별 상품 추천 시스템
2.3 아마존 레코그니션으로 부적절한 동영상 감지
2.4 수요 예측
2.5 아마존 프로드 디텍터를 사용한 가짜 계정 식별
2.6 아마존 메이시를 사용한 정보 유출 탐지 활성화
2.7 대화형 디바이스와 음성 어시스턴트
2.8 텍스트 분석 및 자연어 처리
2.9 인지 검색과 자연어 이해
2.10 지능형 고객 지원 센터
2.11 산업용 AI 서비스와 예측 정비
2.12 AWS IoT와 아마존 세이지메이커를 사용한 홈 자동화
2.13 의료 문서에서 의료 정보 추출
2.14 자체 최적화 및 지능형 클라우드 인프라
2.15 인지 및 예측의 비즈니스 인텔리전스
2.16 차세대 AI/ML 개발자를 위한 교육
2.17 양자 컴퓨팅을 통한 운영체제 프로그램
2.18 비용 절감 및 성능 향상
2.19 마치며
CHAPTER 3 AutoML
3.1 세이지메이커 오토파일럿을 사용한 AutoML
3.2 세이지메이커 오토파일럿을 사용한 트래킹 실험
3.3 세이지메이커 오토파일럿을 사용한 자체 텍스트 분류기 훈련 및 배포
3.4 아마존 컴프리헨드를 사용한 AutoML
3.5 마치며
CHAPTER 4 클라우드로 데이터 수집하기
4.1 데이터 레이크
4.2 아마존 아테나를 사용해 아마존 S3 데이터 레이크 쿼리하기
4.3 AWS 글루 크롤러를 통해 지속적으로 새 데이터 수집하기
4.4 아마존 레드시프트 스펙트럼으로 레이크 하우스 구축하기
4.5 아마존 아테나와 아마존 레드시프트 중에서 선택하기
4.6 비용 절감 및 성능 향상
4.7 마치며
CHAPTER 5 데이터셋 탐색하기
5.1 데이터 탐색을 위한 AWS 도구
5.2 세이지메이커 스튜디오를 사용한 데이터 레이크 시각화
5.3 데이터 웨어하우스 쿼리하기
5.4 아마존 퀵사이트를 사용한 대시보드 생성
5.5 아마존 세이지메이커 및 아파치 스파크를 사용한 데이터 품질 문제 감지
5.6 데이터셋에서 편향 감지하기
5.7 세이지메이커 클래리파이로 다양한 유형의 드리프트 감지
5.8 AWS 글루 데이터브루를 사용한 데이터 분석
5.9 비용 절감 및 성능 향상
5.10 마치며
CHAPTER 6 모델 훈련을 위한 데이터셋 준비
6.1 피처 선택 및 엔지니어링 실행
6.2 세이지메이커 프로세싱을 통한 피처 엔지니어링 확장
6.3 세이지메이커 피처 스토어를 통한 피처 공유
6.4 세이지메이커 데이터 랭글러를 사용한 데이터 수집 및 변환
6.5 아마존 세이지메이커를 사용한 아티팩트 및 익스페리먼트 계보 트래킹
6.6 AWS 글루 데이터브루를 사용한 데이터 수집 및 변환
6.7 마치며
CHAPTER 7 나의 첫 모델 훈련시키기
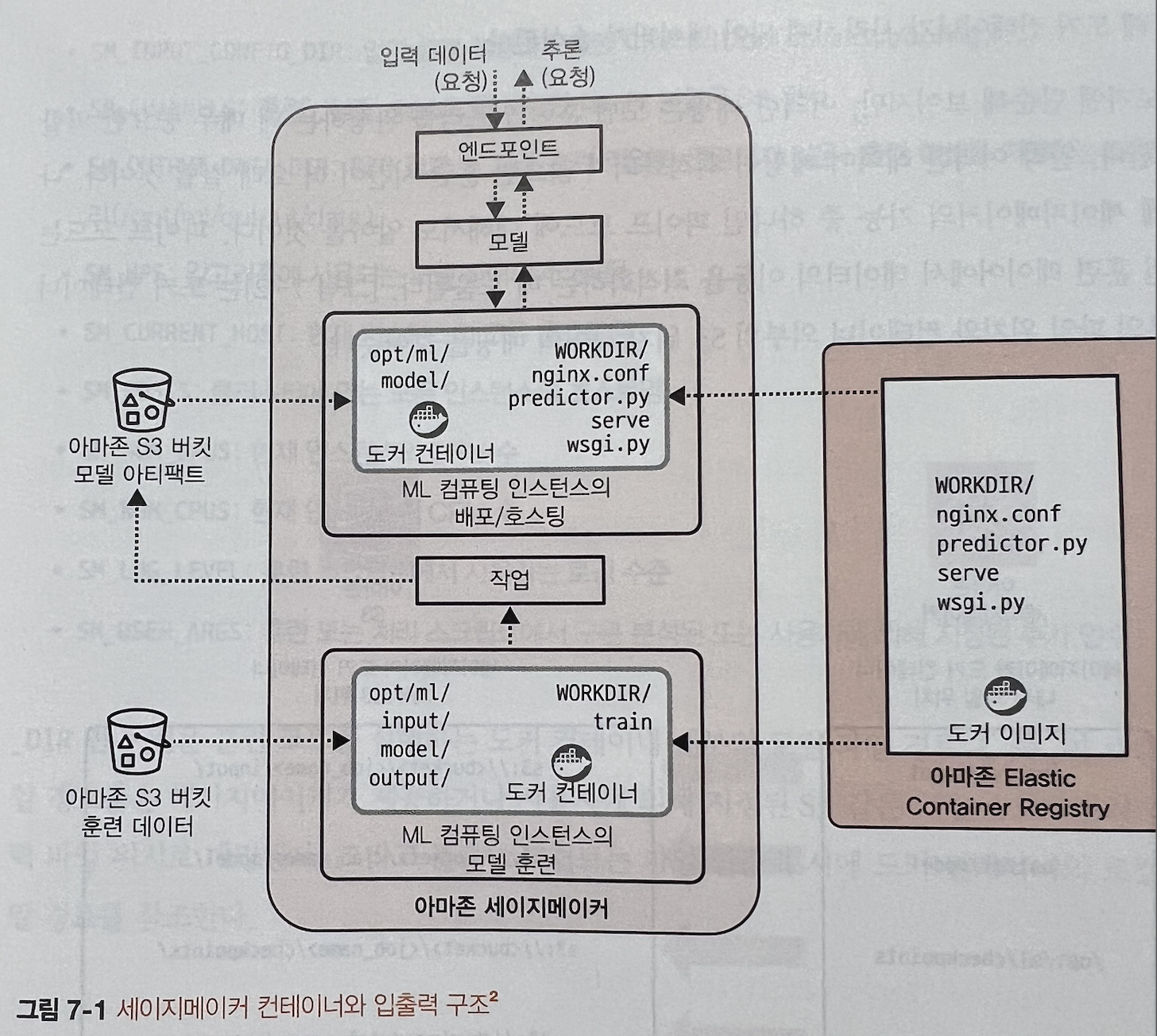
7.1 세이지메이커 인프라 이해하기
7.2 세이지메이커 점프스타트를 사용해 사전 훈련된 BERT 모델 배포하기
7.3 세이지메이커 모델 개발
7.4 자연어 처리 역사
7.5 BERT 트랜스포머 아키텍처
7.6 처음부터 BERT 훈련시키기
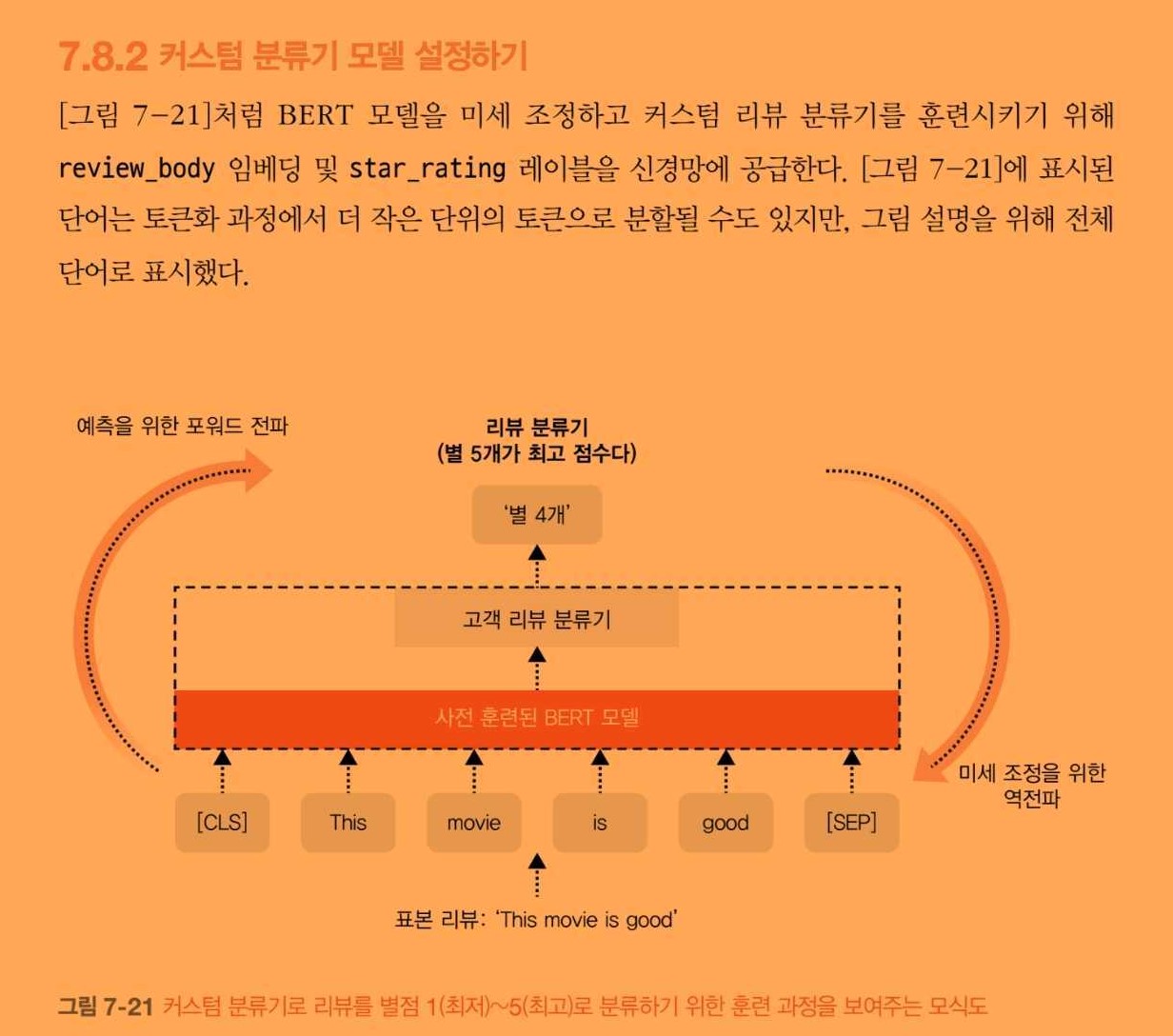
7.7 사전 훈련된 BERT 모델 미세 조정하기
7.8 훈련 스크립트 생성
7.9 세이지메이커 노트북에서 훈련 스크립트 시작하기
7.10 모델 평가하기
7.11 세이지메이커 디버거를 사용한 모델 훈련 디버깅 및 프로파일링
7.12 모델 예측 해석 및 설명
7.13 모델 편향 감지 및 예측 설명
7.14 BERT를 위한 추가 훈련 선택
7.15 비용 절감 및 성능 향상
7.16 마치며
CHAPTER 8 대규모 모델 훈련과 최적화 전략
8.1 최적의 모델 하이퍼파라미터 자동으로 찾기
8.2 세이지메이커 하이퍼파라미터 튜닝에 웜스타트 추가 사용
8.3 세이지메이커 분산 훈련으로 확장하기
8.4 비용 절감 및 성능 향상
8.5 마치며
CHAPTER 9 프로덕션에 모델 배포하기
9.1 실시간 예측 또는 일괄 예측 선택하기
9.2 세이지메이커 엔드포인트를 사용한 실시간 예측
9.3 아마존 클라우드워치를 사용한 세이지메이커 엔드포인트 오토스케일링
9.4 새 모델 또는 업데이트된 모델로 배포하는 전략
9.5 새 모델 테스트 및 비교
9.6 모델 성능 모니터링 및 드리프트 감지
9.7 배포된 세이지메이커 엔드포인트의 데이터 품질 모니터링
9.8 배포된 세이지메이커 엔드포인트의 모델 품질 모니터링하기
9.9 배포된 세이지메이커 엔드포인트의 편향 드리프트 모니터링
9.10 배포된 세이지메이커 엔드포인트의 피처 속성 드리프트 모니터링
9.11 세이지메이커 일괄 변환을 사용한 일괄 예측
9.12 AWS 람다 함수 및 아마존 API 게이트웨이
9.13 엣지에서의 모델 관리 및 최적화
9.14 토치서브를 사용한 파이토치 모델 배포
9.15 AWS DJL을 사용한 텐서플로우-BERT 추론
9.16 비용 절감 및 성능 향상
9.17 마치며
CHAPTER 10 파이프라인과 MLOps
10.1 머신러닝 운영
10.2 소프트웨어 파이프라인
10.3 머신러닝 파이프라인
10.4 세이지메이커 파이프라인을 사용한 파이프라인 오케스트레이션
10.5 세이지메이커 파이프라인으로 자동화하기
10.6 더 많은 파이프라인 종류
10.7 휴먼인더루프 워크플로우
10.8 비용 절감 및 성능 향상
10.9 마치며
CHAPTER 11 스트리밍 데이터 분석과 머신러닝
11.1 온라인 학습과 오프라인 학습의 비교
11.2 스트리밍 애플리케이션
11.3 스트리밍 데이터용 윈도우 쿼리
11.4 AWS에서 스트리밍 분석 및 머신러닝 구현하기
11.5 아마존 키네시스, AWS 람다, 아마존 세이지메이커를 사용한 실시간 상품 리뷰 분류
11.6 아마존 키네시스 데이터 파이어호스를 사용한 스트리밍 데이터 수집 구현
11.7 스트리밍 분석으로 실시간 상품 리뷰 요약하기
11.8 아마존 키네시스 데이터 애널리틱스 설정
11.9 아마존 키네시스 데이터 애널리틱스 애플리케이션
11.10 아파치 카프카, AWS 람다, 아마존 세이지메이커를 사용한 상품 리뷰 분류
11.11 비용 절감 및 성능 향상
11.12 마치며
CHAPTER 12 AWS 보안
12.1 AWS와 사용자 간의 공동 책임 모델
12.2 AWS IAM
12.3 컴퓨팅 및 네트워크 환경 격리
12.4 아마존 S3 데이터 액세스 보호
12.5 저장 시 암호화
12.6 전송 중 암호화
12.7 세이지메이커 노트북 인스턴스 보호
12.8 세이지메이커 스튜디오 보안
12.9 세이지메이커 작업과 모델 보안
12.10 AWS 레이크 포메이션 보호
12.11 AWS 시크릿 매니저를 통한 데이터베이스 자격 증명 보안
12.12 거버넌스
12.13 감사 가능성
12.14 비용 절감 및 성능 향상
12.15 마치며
출판사리뷰
AWS와 데이터 과학의 완벽한 융합을 통해,
비즈니스 성과를 극대화하는 프로젝트를 구축해보세요!
AWS의 다양한 서비스를 활용하여 안정적이고 확장성 있는 데이터 과학 인프라를 구축하는 기업이 많아지고 있습니다. 이 중에는 넷플릭스도 포함되며, EC2, S3, EMR, 레드시프트, 람다 등을 적극적으로 활용하여 비즈니스 성과를 극대화했습니다. 이러한 성과는 다른 기업에게도 큰 영향을 미치게 되었고, 그렇게 AWS 서비스는 데이터 과학 프로젝트에서 필수적인 요소 중 하나로 자리 잡게 되었습니다.
하지만 AWS를 활용하여 데이터 과학을 수행하는 방법에 대한 정보를 한곳에 모아둔 자료는 찾아보기 어렵습니다. 이 책은 이러한 아쉬움을 해결하기 위해, AWS를 활용하여 데이터 과학을 수행하고 비즈니스 성과를 높이기 위한 전체 과정을 안내합니다. 또한, AWS 비용 최적화에 대한 팁과 함께 일반적으로 겪을 수 있는 문제와 그 해결책, 그리고 보안에 대한 정보를 제공합니다. 이 책을 읽고 나면 여러분은 성공적인 데이터 과학 프로젝트를 위한 전문적인 기술과 전략을 숙지하여, 현업에서 높은 수준의 성과를 이룰 수 있게 될 것입니다.
이 책에서 다루는 AWS 서비스 일부 소개
- 스토리지: Amazon EBS, Amazon EFS, Amazon S3 등
- 데이터베이스: Amazon RDS, Amazon DynamoDB, Amazon Aurora, Amazon QLDB 등
- 컴퓨트: Amazon EC2, AWS Lambda, Amazon ECS, Amazon EKS 등
- 인공지능: Amazon SageMaker, Amazon Lex, Amazon Translate, AWS DeepLens 등
- 보안: AWS IAM, AWS KMS, Amazon Macie, AWS Artifact, AWS Config 등
오탈자 등록