책소개
실용적인 데이터 엔지니어링의 세계로 이끄는 최고의 안내서!
고객 요구 사항에 맞는 시스템을 계획하고 구축하는 방법
데이터 엔지니어링 분야가 빠르게 성장하면서 많은 소프트웨어 엔지니어와 데이터 과학자, 분석가가 해당 분야에 대한 포괄적인 관점을 새롭게 모색하고 있다. 이 실용적인 책은 데이터 엔지니어링 수명 주기의 프레임워크를 소개하고 사용 가능한 최고의 기술을 평가한다. 또한 다양한 클라우드 기술을 결합함으로써 다운스트림 데이터를 소비하는 조직과 고객의 요구 사항에 따라 시스템을 계획하고 구축하는 구체적인 방법을 알려준다. 이 책을 다 읽고 나면 기본 기술과 관계없이 모든 데이터 환경에 중요한 데이터 생성, 수집, 오케스트레이션, 변환, 저장 및 거버넌스의 개념을 적용하는 방법을 이해할 수 있다.

저자소개

목차
[PART I 데이터 엔지니어링 기반 구축하기]
CHAPTER 1 데이터 엔지니어링 상세
_1.1 데이터 엔지니어링이란?
_1.2 데이터 엔지니어링 기술과 활동
_1.3 조직 내 데이터 엔지니어
_1.4 결론
_1.5 참고 문헌
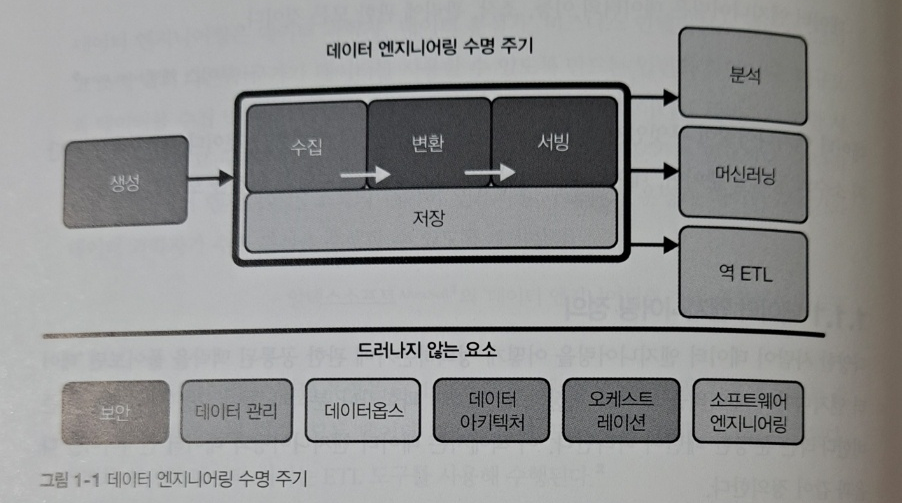
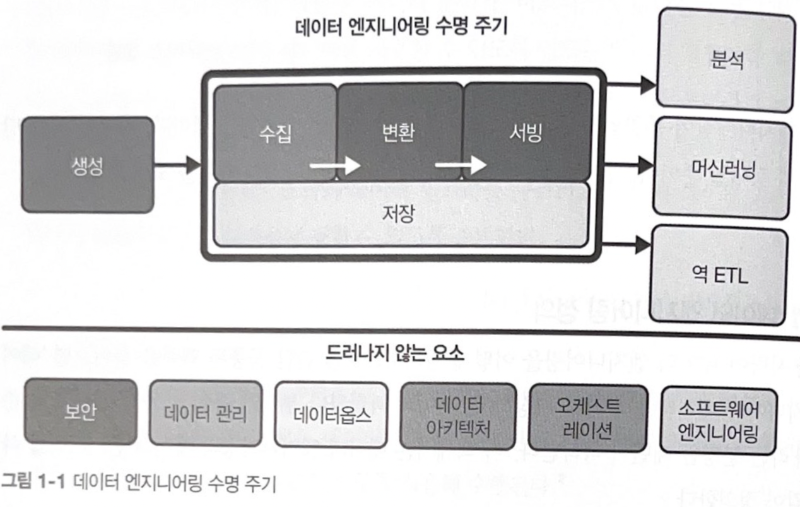
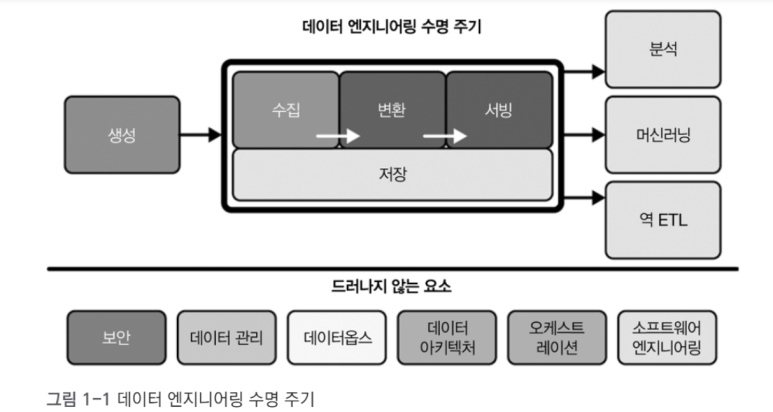
CHAPTER 2 데이터 엔지니어링 수명 주기
_2.1 데이터 엔지니어링 수명 주기란?
_2.2 데이터 엔지니어링 수명 주기의 드러나지 않는 주요 요소
_2.3 결론
_2.4 참고 문헌
CHAPTER 3 우수한 데이터 아키텍처 설계
_3.1 데이터 아키텍처란?
_3.2 우수한 데이터 아키텍처의 원칙
_3.3 주요 아키텍처 개념
_3.4 데이터 아키텍처의 사례 및 유형
_3.5 데이터 아키텍처 설계 담당자는 누구인가?
_3.6 결론
_3.7 참고 문헌
CHAPTER 4 데이터 엔지니어링 수명 주기 전체에 걸친 기술 선택
_4.1 팀의 규모와 능력
_4.2 시장 출시 속도
_4.3 상호 운용성
_4.4 비용 최적화 및 비즈니스 가치
_4.5 현재 vs 미래: 불변의 기술과 일시적 기술 비교
_4.6 장소: 온프레미스, 클라우드, 하이브리드 클라우드, 멀티클라우드
_4.7 구축과 구매 비교
_4.8 모놀리식과 모듈식 비교
_4.9 서버리스와 서버 비교
_4.10 최적화, 성능, 벤치마크 전쟁
_4.11 데이터 엔지니어링 수명 주기의 드러나지 않는 요소
_4.12 결론
_4.13 참고 문헌
[PART II 데이터 엔지니어링 수명 주기 심층 분석]
CHAPTER 5 1단계: 원천 시스템에서의 데이터 생성
_5.1 데이터 원천: 데이터는 어떻게 생성될까?
_5.2 원천 시스템: 주요 아이디어
_5.3 원천 시스템의 실질적인 세부 사항
_5.4 함께 작업할 대상
_5.5 드러나지 않는 요소가 원천 시스템에 미치는 영향
_5.6 결론
_5.7 참고 문헌
CHAPTER 6 2단계: 데이터 저장
_6.1 데이터 스토리지의 기본 구성 요소
_6.2 데이터 스토리지 시스템
_6.3 데이터 엔지니어링 스토리지 개요
_6.4 스토리지의 주요 아이디어와 동향
_6.5 함께 작업할 대상
_6.6 드러나지 않는 요소
_6.7 결론
_6.8 참고 문헌
CHAPTER 7 3단계: 데이터 수집
_7.1 데이터 수집이란?
_7.2 수집 단계의 주요 엔지니어링 고려 사항
_7.3 배치 수집 고려 사항
_7.4 메시지 및 스트림 수집에 관한 고려 사항
_7.5 데이터 수집 방법
_7.6 함께 일할 담당자
_7.7 드러나지 않는 요소
_7.8 결론
_7.9 참고 문헌
CHAPTER 8 4단계: 쿼리 모델링 및 데이터 변환
_8.1 쿼리
_8.2 데이터 모델링
_8.3 변환
_8.4 함께 일할 담당자
_8.5 드러나지 않는 요소
_8.6 결론
_8.7 참고 문헌
CHAPTER 9 5단계: 분석, 머신러닝 및 역 ETL을 위한 데이터 서빙
_9.1 데이터 서빙의 일반적인 고려 사항
_9.2 분석
_9.3 머신러닝
_9.4 데이터 엔지니어가 ML에 관해 알아야 할 사항
_9.5 분석 및 ML을 위한 데이터 서빙 방법
_9.6 역 ETL
_9.7 함께 작업하는 사람
_9.8 드러나지 않는 요소
_9.9 결론
_9.10 참고 문헌
[PART III 보안, 개인정보보호 및 데이터 엔지니어링의 미래]
CHAPTER 10 보안과 개인정보보호
_10.1 사람
_10.2 프로세스
_10.3 기술
_10.4 결론
_10.5 참고 문헌
CHAPTER 11 데이터 엔지니어링의 미래
_11.1 사라지지 않는 데이터 엔지니어링 수명 주기
_11.2 복잡성의 감소와 사용하기 쉬운 데이터 도구의 부상
_11.3 클라우드 규모의 데이터 OS와 향상된 상호 운용성
_11.4 ‘엔터프라이즈’ 데이터 엔지니어링
_11.5 직책과 책임의 변화
_11.6 모던 데이터 스택을 넘어 라이브 데이터 스택으로
_11.7 결론
APPENDIX A 직렬화와 압축 기술 상세
APPENDIX B 클라우드 네트워킹
에필로그
찾아보기
출판사리뷰
현업 데이터 엔지니어들이 먼저 알아본 화제의 그 책!
데이터 파이프라인 설계와 구축의 핵심 원칙을 한 권에!
이 책은 특정 도구, 기술 또는 플랫폼을 사용하는 데이터 엔지니어링을 다루지 않는다. 이러한 관점에서 데이터 엔지니어링 관련 기술에 접근하는 도서는 많지만, 그런 책들은 수명이 짧다. 대신 이 책은 데이터 엔지니어링 이면의 기본 개념에 초점을 맞춘다.
이 책의 목표는 현재의 데이터 엔지니어링 관련 내용과 자료의 공백을 메우는 것이다. 특정 데이터 엔지니어링 도구와 기술을 다루는 기술 자원이 부족한 것은 아니지만, 사람들은 이러한 구성 요소들을 실제 세계에 적용되는 일관된 전체적 결과물로 조립하는 방법을 이해하는 데 어려움을 겪는다. 이 책은 데이터 수명 주기의 시작 단계부터 최종 단계에 이르기까지 모든 단계를 살펴본다. 특히 분석가, 데이터 과학자, 머신러닝 엔지니어와 같은 다운스트림 데이터 소비자의 요구를 충족하기 위해 다양한 기술을 결합하는 방법을 보여준다. 한편으로는 특정 기술, 플랫폼, 프로그래밍 언어의 세부 사항을 다루는 오라일리 도서들을 보완하는 역할을 한다.
이 책의 주요 내용은 데이터 생성, 저장, 수집, 변환, 서빙 등을 다루는 데이터 엔지니어링 수명 주기다. 데이터의 태동기 이후 우리는 수많은 특정 기술과 공급업체 제품의 흥망성쇠를 목격했지만, 데이터 엔지니어링 수명 주기 단계는 본질적으로 바뀌지 않았다. 이 프레임워크를 통해 독자는 기술을 실제 비즈니스 문제에 적용하는 데 필요한 올바른 이해를 얻을 수 있다.
여기서 우리의 목표는 두 가지 축을 아우르는 원칙을 세우는 것이다. 첫째, 데이터 엔지니어링을 모든 관련 기술을 포괄하는 원칙으로 정제하고자 한다. 둘째, 오랜 시간이 지나도 변함없는 원칙을 제시하고자 한다. 이러한 아이디어가 지난 20년간의 데이터 기술 격변기를 거치며 얻은 교훈을 반영하고, 우리의 내적 프레임워크가 미래에도 10년 이상 유용하게 유지되기를 바란다.
- 서문 ‘이 책에 대하여’ 중에서
오탈자 등록