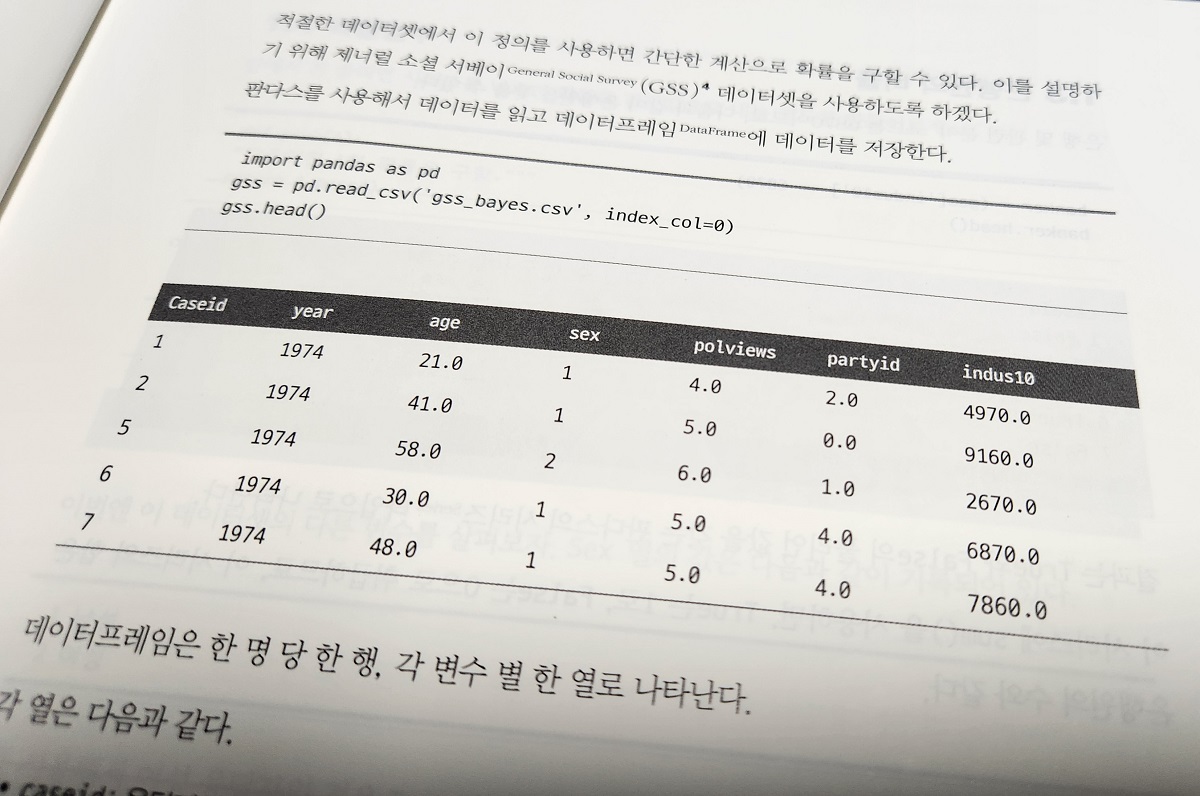
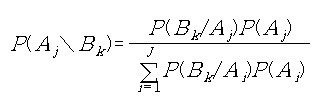책소개
베이지안으로 생각하고 프로그래밍하라
베이지안 통계를 마주하는 데는 프로그래밍으로 충분하다. 이 책을 읽고 나면 통계 문제를 수식 대신 파이썬 코드로, 연속 확률 분포 대신 이산 확률 분포를 사용해서 풀 수 있게 된다. 골치 아픈 수학 대신 프로그래밍을 통해 베이지안 기초 지식을 이해하고, 통계 기법 하나하나를 실생활 문제에 적용해보자.
베이지안 통계 기법이 더 보편화되고 더욱 주목받고 있지만, 초심자가 볼 만한 자료는 별로 없다. 이 책은 저자 앨런 B. 다우니의 대학교 학부 강의를 기반으로 한 계산 접근법으로 베이지안 통계에 순조롭게 접근하도록 도와준다.
저자소개

목차
CHAPTER 1 확률
1.1 은행원 린다
1.2 확률
1.3 은행원의 비율
1.4 확률함수
1.5 정치관과 정당
1.6 논리곱
1.7 조건부확률
1.8 조건부확률은 교환 가능하지 않다
1.9 조건과 논리곱
1.10 확률 법칙
1.11 요약
1.12 연습 문제
CHAPTER 2 베이즈 정리
2.1 쿠키 문제
2.2 통시적 베이즈
2.3 베이즈 테이블
2.4 주사위 문제
2.5 몬티 홀 문제
2.6 요약
CHAPTER 3 분포
3.1 분포
3.2 확률질량함수
3.3 다시 만난 쿠키 문제
3.4 101개의 쿠키 그릇
3.5 주사위 문제
3.6 주사위 갱신
3.7 요약
3.8 연습 문제
CHAPTER 4 비율 추정
4.1 유로 동전 문제
4.2 이항분포
4.3 베이지안 추정
4.4 삼각사전분포
4.5 이항가능도함수
4.6 베이지안 통계
4.7 요약
4.8 연습 문제
CHAPTER 5 수량 추정
5.1 기관차 문제
5.2 사전확률에 대한 민감도
5.4 신뢰구간
5.5 독일 탱크 문제
5.6 정보성 사전확률
5.7 요약
5.8 연습 문제
CHAPTER 6 공산과 가산
6.1 공산
6.2 베이즈 규칙
6.3 올리버의 혈액형
6.4 가산
6.5 글루텐 민감도
6.6 일반 연산 문제
6.7 역산 문제
6.8 요약
6.9 연습 문제
CHAPTER 7 최솟값, 최댓값 그리고 혼합 분포
7.1 누적분포함수
7.2 넷 중 높은 값
7.3 최댓값
7.4 최솟값
7.5 혼합
7.6 일반적인 혼합
7.7 요약
CHAPTER 8 포아송 과정
8.1 월드컵 문제
8.2 포아송 분포
8.3 감마 분포
8.4 갱신
8.5 우세할 확률
8.6 다음 경기 예측
8.7 지수분포
8.8 요약
8.9 연습 문제
CHAPTER 9 의사결정분석
9.1 ‘그 가격이 적당해요’ 문제
9.2 사전분포
9.3 커널 밀도 추정
9.4 오차분포
9.5 갱신
9.6 우승 확률
9.7 의사결정분석
9.8 예상 수익 최대화
9.9 요약
9.10 논의
CHAPTER 10 검정
10.1 추정
10.2 증거
10.3 균등분포 형태의 치우침
10.4 베이지안 가설 검정
10.5 베이지안 밴딧
10.6 사전 믿음
10.7 갱신
10.8 여러 개의 밴딧
10.9 탐색과 활용
10.10 전략
10.11 요약
10.12 연습 문제
CHAPTER 11 비교
11.1 외적 연산
11.2 A의 키는 얼마인가?
11.3 결합분포
11.4 결합분포 시각화
11.5 가능도
11.6 갱신
11.7 주변분포
11.8 사후조건부확률
11.9 의존성과 독립성
11.10 요약
CHAPTER 12 분류
12.1 펭귄 데이터
12.2 정규 모델
12.3 갱신
12.4 나이브 베이지안 분류
12.5 결합분포
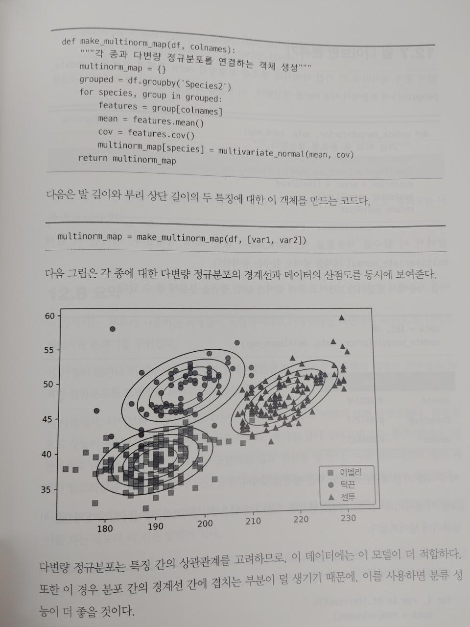
12.6 다변량 정규분포
12.7 덜 나이브한 분류기
12.8 요약
12.9 연습 문제
CHAPTER 13 추론
13.1 독해 능력 향상
13.2 매개변수 추정
13.3 가능도
13.4 사후 주변분포
13.5 차이의 분포
13.6 요약통계 사용하기
13.7 요약통계 갱신
13.8 주변분포 비교
13.9 요약
CHAPTER 14 생존 분석
14.1 와이불 분포
14.2 불완전한 데이터
14.3 불완전한 데이터 사용하기
14.4 전구
14.5 사후평균
14.6 사후예측분포
14.7 요약
14.8 연습 문제
CHAPTER 15 표식과 재포획
15.1 그리즐 곰 문제
15.2 갱신
15.3 두 개의 매개변수를 사용하는 모델
15.4 사전분포
15.5 갱신
15.6 링컨 지수 문제
15.7 세 개의 매개변수를 사용하는 모델
15.8 요약
CHAPTER 16 로지스틱 회귀
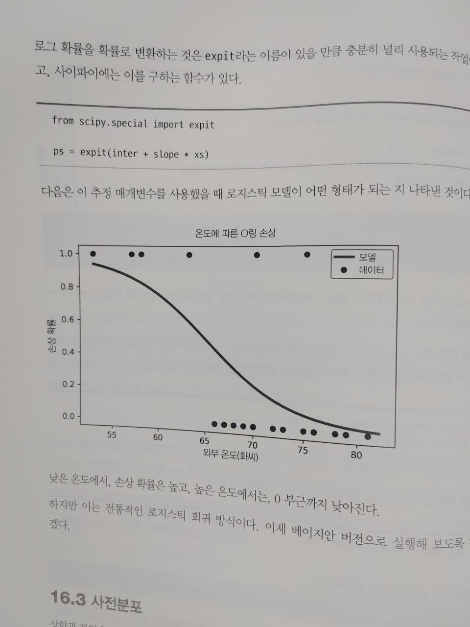
16.1 로그 공산
16.2 우주 왕복선 문제
16.3 사전분포
16.4 가능도
16.5 갱신
16.6 주변분포
16.7 분포변환
16.8 예측분포
16.9 실증적 베이지안 방법론
16.10 요약
16.11 연습 문제
CHAPTER 17 회귀
17.1 더 많은 눈이 내렸을까?
17.2 회귀모델
17.3 최소제곱회귀
17.4 사전분포
17.5 가능도
17.6 갱신
17.7 마라톤 세계 신기록
17.8 사전분포
17.9 예측
17.10 요약
17.11 연습 문제
CHAPTER 18 켤레사전분포
18.1 다시 만난 월드컵 문제
18.2 켤레사전분포
18.3 실제값은 어떤가?
18.4 이항가능도
18.5 사자, 호랑이 그리고 곰
18.6 디리클레 분포
18.7 요약
18.8 연습 문제
CHAPTER 19 MCMC
19.1 월드컵 문제
19.2 그리드 근사
19.3 사전 예측분포
19.4 PyMC3 소개
19.5 사전분포 표본 추출
19.6 언제 추론에 다다를 수 있을까?
19.7 사후예측분포
19.8 행복
19.9 단순회귀
19.10 다중회귀
19.11 요약
CHAPTER 20 근사 베이지안 계산
20.1 신장 종양 문제
20.2 단순성장모델
20.3 보다 일반적인 모델
20.4 시뮬레이션
20.5 근사 베이지안 계산
20.6 세포 수 측정
20.7 ABC를 사용한 세포 수 측정
20.8 추정하는 부분은 언제 구할까?
20.9 요약
20.10 연습 문제
출판사리뷰
일상에서 쉽게 접할 수 있는 사건으로 배우는 베이지안 통계
베이지안 통계를 다루는 대부분의 책에서는 수학 기호와 미적분 같은 수학적 개념을 적용해 생각을 표현합니다. 이 책에서는 수학적 개념 대신 파이썬 코드를 사용하고, 연속적 수학 대신 이산적 가정을 사용합니다. 적분은 합으로, 확률 분포 연산은 반복문이나 행렬 연산으로 나타냅니다.
이렇게 일상에서 쉽게 접할 법한 일을 기반으로, 개발자에게 손쉬우면서 일반인도 배우기 쉬운 파이썬 프로그래밍 언어로 통계학을 풀어내고 있습니다. 술술 읽히며 어느새 집중하게 되는 저자의 실생활 예제와 간단한 코드로 데이터에 새로운 시각을 더해봅시다.
대상 독자
주요 내용
추천사
저자는 이번에도 200년이 넘은 수학 이론에 실생활 사례를 접목해 유익함과 재미를 한 번에 잡았다. 이 책은 베이즈 정리를 소개하는 최고의 응용서다.
_라빈 쿠마, 데이터 과학자
저자는 독특한 예제와 다양한 응용 사례를 제시하며 효과적으로 베이지안 통계에 접근한다. 베이지안 사고는 점점 보편화되며 문제 해결에 널리 사용되고 있다.
_토마스 닐드, 닐드 컨설팅 그룹 설립자이자 『Getting Started with SQL』 저자
오탈자 등록