책소개
아이디어가 현실이 되는, 나만의 머신러닝 애플리케이션 구현하기
머신러닝 기반 애플리케이션을 설계, 구축, 배포하는 과정에 필요한 모든 기술을 설명하는 책이다. 초기 아이디어가 제품으로 개발되기까지의 과정을 머신러닝 에디터 예제 프로젝트를 통해 순서대로 배운다. 데이터 과학자, 소프트웨어 엔지니어, 제품 관리자가 머신러닝 애플리케이션을 단계별로 구현하는 데 필요한 도구와 실무에서 맞닥뜨리게 되는 도전 과제와 모범 사례를 살펴본다. 유용한 코드와 친절한 그림, 업계 리더와의 인터뷰를 통해 실용적인 머신러닝 개념을 터득해 본인만의 머신러닝 애플리케이션을 자신 있게 구현해보자.
대상 독자
주요 내용
부별 요약
추천사
머신러닝에서 가장 어려운 부분인 문제 정의, 모델 디버깅, 배포를 건너뛰는 책은 너무나 많습니다. 하지만 이 책은 이런 문제에 초점을 맞춰 이야기를 풀어갑니다. 이 책을 읽으면 아이디어에 불과했던 프로젝트를 큰 영향을 발휘하는 애플리케이션으로 만들 수 있습니다.
_알렉산더 구드, Intuit 데이터 과학자
머신러닝 모델을 도입하는 방법, 잘못되기 쉬운 부분과 특별히 주의해야 할 사항에 대한 실용적인 조언을 찾고 있다면 바로 이 책이 답입니다. 10년 전에 이 책을 읽었더라면, 교훈을 찾아 헤매던 시간을 단축할 수 있었을 겁니다.
_루카스 텐서, 트위치 ML 수석 매니저

저자소개


목차
[PART I 올바른 머신러닝 접근 방법 모색]
CHAPTER 1 제품의 목표를 머신러닝 문제로 표현하기
1.1 어떤 작업이 가능한지 예상하기
1.2 머신러닝 에디터 설계
1.3 모니카 로가티: 머신러닝 프로젝트의 우선순위 지정하기
1.4 마치며
CHAPTER 2 계획 수립하기
2.1 성공 측정하기
2.2 작업 범위와 문제점 예상하기
2.3 머신러닝 에디터 계획하기
2.4 규칙적인 향상 방법: 간단하게 시작하기
2.5 마치며
[PART II 초기 프로토타입 제작]
CHAPTER 3 엔드투엔드 파이프라인 만들기
3.1 가장 간단한 프로토타입
3.2 머신러닝 에디터 프로토타입
3.3 워크플로 테스트하기
3.4 머신러닝 에디터 프로토타입 평가
4.5 마치며
CHAPTER 4 초기 데이터셋 준비하기
4.1 반복적인 데이터셋
4.2 첫 번째 데이터셋 탐색하기
4.3 레이블링으로 데이터 트렌드 찾기
4.4 데이터를 활용한 특성 생성과 모델링
4.5 로버트 먼로: 데이터를 찾고, 레이블링하고, 활용하는 방법
4.6 마치며
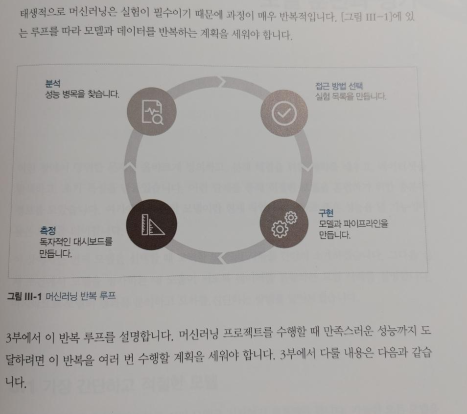
[PART III 모델 반복]
CHAPTER 5 모델 훈련과 평가
5.1 가장 간단하고 적절한 모델
5.2 모델 평가: 정확도를 넘어서
5.3 특성 중요도 평가
5.4 마치며
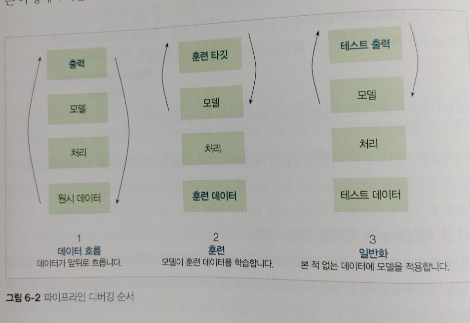
CHAPTER 6 머신러닝 문제 디버깅
6.1 소프트웨어 모범 사례
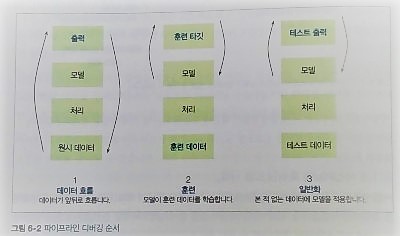
6.2 데이터 흐름 디버깅: 시각화와 테스트
6.3 훈련 디버깅: 모델 학습하기
6.4 일반화 디버깅: 유용한 모델 만들기
6.5 마치며
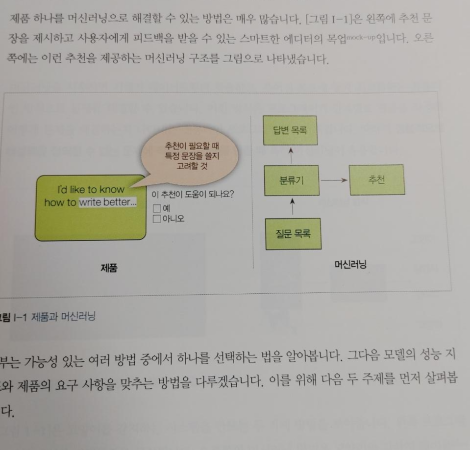
CHAPTER 7 분류기를 사용한 글쓰기 추천
7.1 모델로 추천 만들기
7.2 모델 비교하기
7.3 추천 생성하기
7.4 마치며
[PART IV 배포와 모니터링]
CHAPTER 8 모델 배포 시 고려 사항
8.1 데이터 고려 사항
8.2 모델링 고려 사항
8.3 크리스 할랜드: 배포 실험
8.4 마치며
CHAPTER 9 배포 방식 선택
9.1 서버 측 배포
9.2 클라이언트 측 배포
9.3 연합 학습: 하이브리드 방법
9.4 마치며
CHAPTER 10 모델 안전장치 만들기
10.1 실패를 대비하는 설계
10.2 성능 설계
10.3 피드백 요청
10.4 크리스 무디: 데이터 과학자에게 모델 배포 권한 부여
10.5 마치며
CHAPTER 11 모니터링과 모델 업데이트
11.1 모니터링의 역할
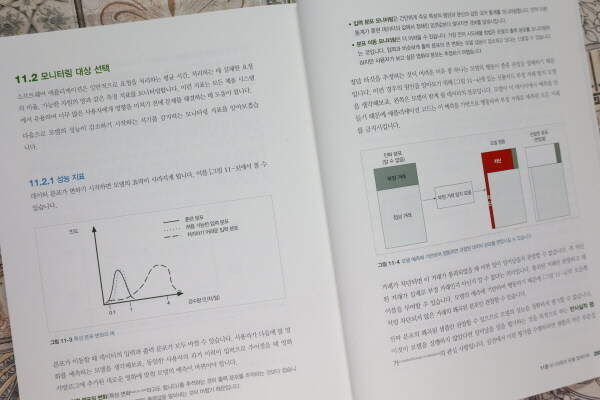
11.2 모니터링 대상 선택
11.3 머신러닝을 위한 CI/CD
11.4 마치며
출판사리뷰
머신러닝 아이디어 생각만 하고 있었다면?
지금 바로 애플리케이션 개발에 힘을 실어줄 강력한 한 방!
머신러닝이 점점 더 활발하게 다양한 제품에 사용되면서, 새로운 제품 개발에 대한 아이디어가 번쩍번쩍 샘솟는 분들이 많을 겁니다. 생각에만 그치지 않고 아이디어를 실제 애플리케이션으로 구현하고 싶은데 어떤 것부터, 어디서부터 시작해야 할지 모르겠다면 바로 이 책을 펼쳐보세요. 대부분의 머신러닝 책이 알고리즘과 라이브러리 설명에 중점을 두는 것과 달리, 이 책은 머신러닝 기반의 애플리케이션 아이디어가 실제 애플리케이션으로 구현되는 모든 과정을 살펴봅니다. 실무자가 실제로 애플리케이션을 구현할 때 필요한 도구와 마주하게 될 도전 과제를 살펴보고, 업계 리더 4명의 생생한 경험이 담긴 인터뷰를 통해 유용한 팁을 얻어 본인만의 스킬을 쌓아가세요. 이 책을 읽고 나면 본인만의 머신러닝 애플리케이션을 구현하는 과정의 첫 삽을 자신 있게 뜰 수 있을 겁니다.
오탈자 등록