한빛미디어의 “실전 아파치 카프카”를 리뷰합니다.

작년에 빅데이터 IoT 시스템 구축 프로젝트에 참여하면서, 그동안 하둡과 카프카, 스파크에 대해서는 가벼운 지식만이 있었을 뿐이었고, 당시 클라이언트 업무를 하고 있어서 프로젝트를 참여한 김에 학습을 하고 세미나를 진행한 적이 있었습니다. 대학원 전공도 웹서버 클러스터링이어서 어떤 분야보다 관심이 많이 가지게 되었습니다. 이번에 “실전 아파치 카프카” 리뷰를 하게 되어 도서를 리뷰함과 동시에 다시 한번 학습 내용을 정리할 수 있는 좋은 기회가 되었습니다.
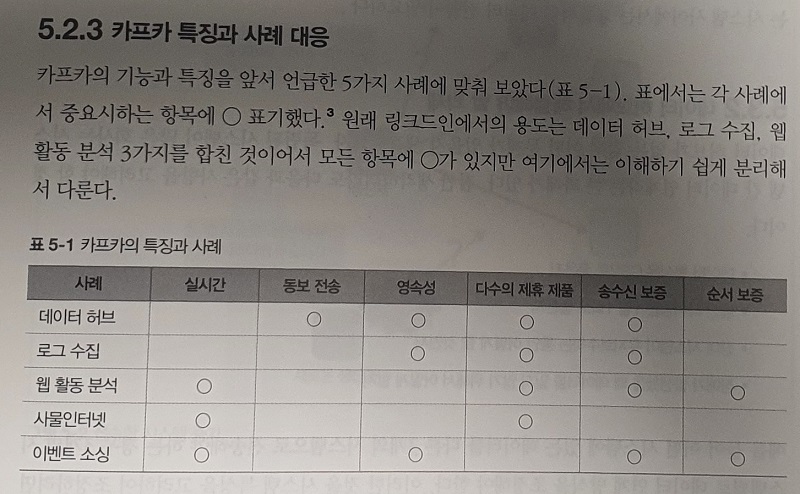
결론적으로 말씀 드리면 하고자 “실전 아파치 카프카”는 굉장히 만족스러운 도서 내용을 가지고있습니다. 쿠버네티스나 도커, 하둡과 같은 주제를 다루는 도서들은 많은데, 아쉬웠던 부분은 인프라 측면 위주로 다루는 경우가 많았습니다. “실전 아파치 카프카”는 Kafka 자체 뿐만 아니라 Kafka와 연동되는 시스템 만드는 것을 실습하고 Kafka를 실제 외부 시스템들과 연동하여 구축하는 것에 도서 후반기에 많은 비중으로 다루고 있습니다. 가령 카프카를 주제로 한다면 Producer와 Consumer 뿐만 아니라 connector와 stream에 대해서도 다뤄야 하기에 카프카 기본 컴포넌트들에 대해서 얼마나 충실하게 다루고 있는지 살펴봐야 하고, 실제 IoT나 빅데이터 시스템에 응용할 있는지를 살펴봐야 하는데, 본 도서는 카프카 자체에 대한 내용의 충실성 뿐만 아니라 5장부터 “Part 2 실전 아파치 카프가”라는 주제를 가지고 11장까지 카프라를 이용한 인프라 구성과 응용을 상세히 다루고 있어서 높은 점수를 주고 싶습니다.
Kafka publish-subscribe
카프카를 다루는 도서나 블로그에서 도입으로 나오는 내용이 탄생 배경으로 LinkedIn 개발자에 의해서 개발되었고 LinkedIn 로그 처리와 웹사이트 활동 추적을 목적으로 적용되어 사용되었다는 내용입니다. 분산 메시징 시스템으로써 2011년에 오픈소스로 공개되었고, 대용량의 메시지 처리에서도, 특히 실시간 로그 처리에 특화된 아키텍처 설계를 기반으로 합니다.

근래의 사물인터넷 시스템이나 빅데이터 시스템과 같이 메시지의 높은 동시성으로 인해 대량의 데이터를 높은 처리량과 실시간으로 처리하기 위해 만들어졌기 때문에 기존 RabbitMQ나 ActiveMQ와 같은 메시징 시스템들보다 우수하다고 합니다.
그리고 실제로 많은 대용량 메세지를 다루고 있는 시스템에서 카프카를 많이 사용하는 것으로 알려져 있습니다. 이러한 이유로로 채용 시장에서도 하둡이나 카프카, 스파크와 같이 대용량 메세지 처리 시스템에 대한 유경험자에 대한 구애가 많은 것으로 보입니다.
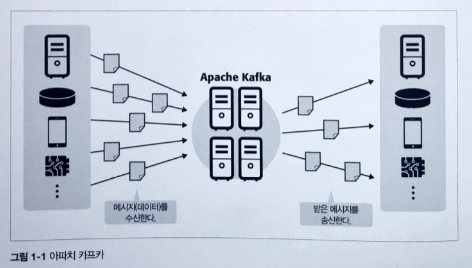
Kafka는 발행-구독(publish-subscribe) 모델을 기반입니다. RabbitMQ와 같은 기존 MQTT Broker에서의 Pub(발행인)과 Sub(구독자) 간의 메세징 중계 모델과유사하고 따라서 MQTT Broker의 producer, consumer, broker와 같은 구성입니다. 다만 10장에서 언급되는 내용으로 IoT 사물인터넷의 경우 MQTT 메세징을 많이 사용하는데, MQTT 브로커가 kafka에서는 존재하지 않기 때문에 IoT 시스템을 구성한다면 MQTT 브로커와 연동해야 겠지요.
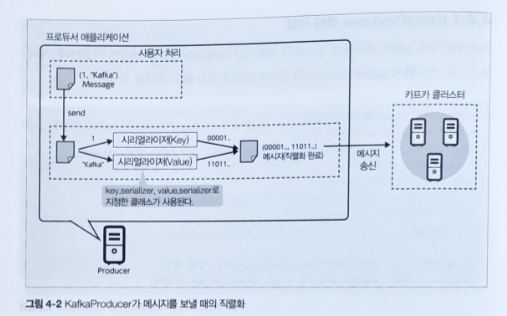
KafkaProducer
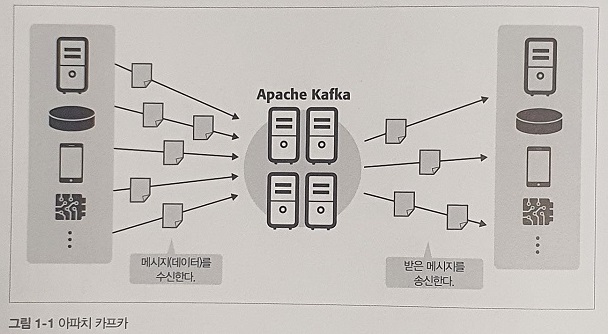
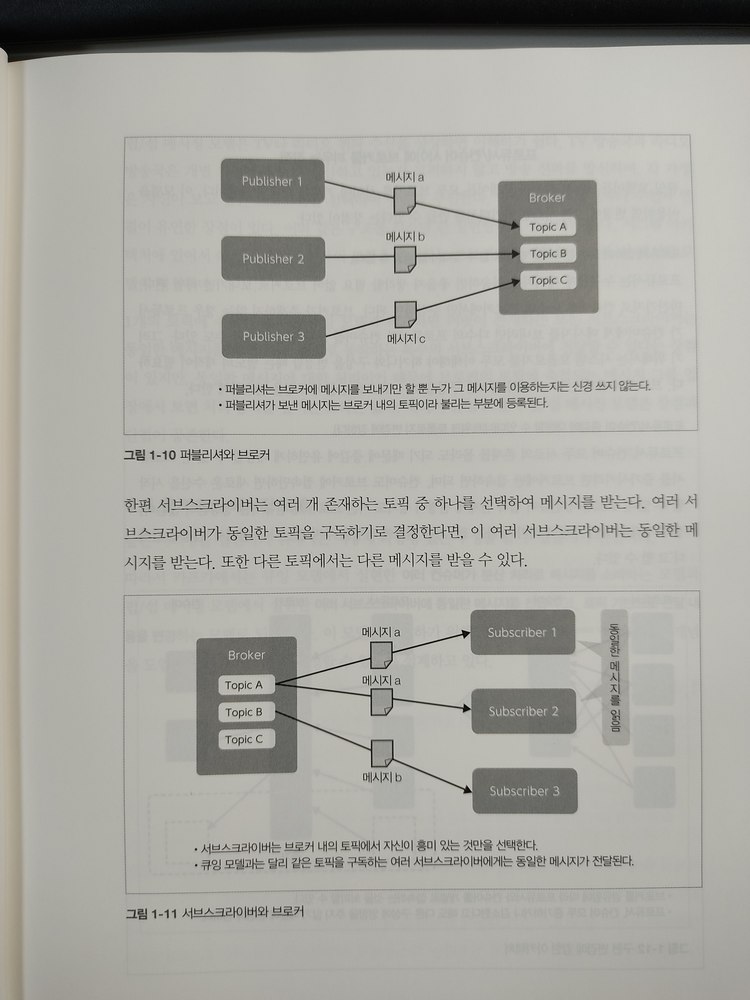
카프카의 브로커는 토픽(topic)으로 메시지를 관리합니다. 프로듀서(Publisher)는 브로커에 메세지를 보낼 뿐, 누가 그 메시지를 이용하는지 신경 쓰지 않습니다. 퍼블리셔가 보낸 메시지는 브로커 내 토픽(Topic)으로 메세지를 생성하여 등록합니다.
브로커가 전달받은 메시지를 토픽(topic)으로 분류하여 쌓아 으면, 해당 토픽을 구독하는 컨슈머(consumer)가 메시지를 가져가서 처리하게 됩니다.

KafkaConsumer컨슈머(Subscriber)는 여러 개 존재하는 토픽(Topic) 중 하나를 선택하여 메시지를 받습니다. 카프카 컨슈머 어플리케이션 개발을 4.5장에서 직접 구현해봅니다. 1초마다 받은 메시지를 콘솔에서 표시하는 어플리케이션 예제입니다.


Kafka 응용
Part 2 실전 아파치 카프카에서는 실제 응용에 대해서 내용을 다룹니다. 5장 카프카 사례에서 IoT 시스템과 로그 시스템을 예로 들어 카프카를 적용하여 응용한 것을 설명하고 있습니다.

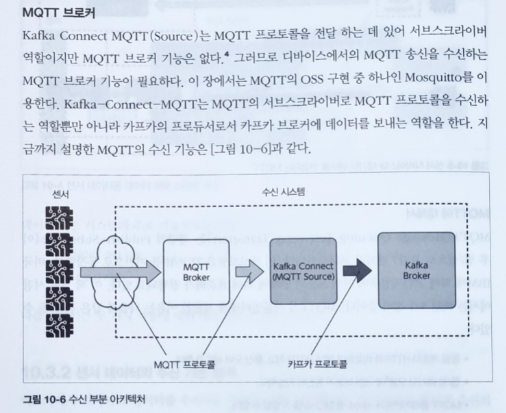
이는 뒤에 7장과 9장, 10장에서 빅데이터 시스템과 IoT 시스템에 대해서 더욱 자세히 다루고 있습니다. IoT 시스템과 같은 경우는 기존 MQTT 기반의 브로커들과의 연동도, 왜 연동이 필요한지, 어떻게 연동할 수 있는지 내용을 서술하고 있습니다.

스파크 연동에 대해서는, 실제로 빅데이터 시스템을 구축한다면 하둡과 스파크와 연동해서 구성될 가능성이 큽니다. 9장에서는 스파크의 structured streaming에 의한 스트림 처리라는 주제로 스파크와 연동하는 것을 다룹니다. 스파크의 데이터 처리 모델과 RDD, DataFrame과 Dataset에 대해서 1장을 아낌없이 설명하고 있습니다.
독서를 마치고 나서
베타리더의 글 중에서 저자의 포스가 느껴진다는 소감을을 보았는데, 저 역시 그러한 느낌을 강하게 받았습니다. 어떤 프레임워크나 라이브러리든 API 문서가 제일 좋은 가이드 문서인데, 보통 API 문서는 딱딱함의 결정체이고 내용에 대한 이해가 결코 쉽진 않기 때문에 도서 구매를 통해서 좀더 쉽게 이해하기 위해서 가이드를 받는다고 생각합니다. 카프카의 경우 브로커 역할을 하기 때문에 카프카 자체만을 포커스해서 서술했다면 부실한 도서라는 오명을 받을 수 있습니다. 허나 IoT나 파일, RDBMS와 스파크까지 여러가지 상황을 고려해서 응용하는 것에 많은 지면 내용을 할애했다는 것에 매우 만족스러운 도서이고, 다시 한번 저자들의 내공을 알 수 있는 도서 였습니다.

현재의 대규모 사이트에는 카프카 적용이 기본이 되는 것으로 보입니다. IoT 뿐만 아니라 빅데이터 시스템, connected-car 등 대량의 데이터를 실시간으로 처리해야 하고, 다른 에코 시스템과 원활히 통합할 수 있어야 하는 요건에 부합되어 앞으로도 카프카의 적용과 활용, 확장은 기대할만 합니다. 저자들의 내공이 대단하다는 느낌을 앞서 말씀 드렸는데, 그들의 풍부한 경험과 지식을, 도서의 API 활용과 응용에 많은 지면을 할애줘서 감사하다는 인사를 건네고 싶고, 이런 좋은 도서가 폭넓게 읽혀져서 플랫폼 구축과 활용에 초석이 되는 도서가 되기를 바라겠습니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."