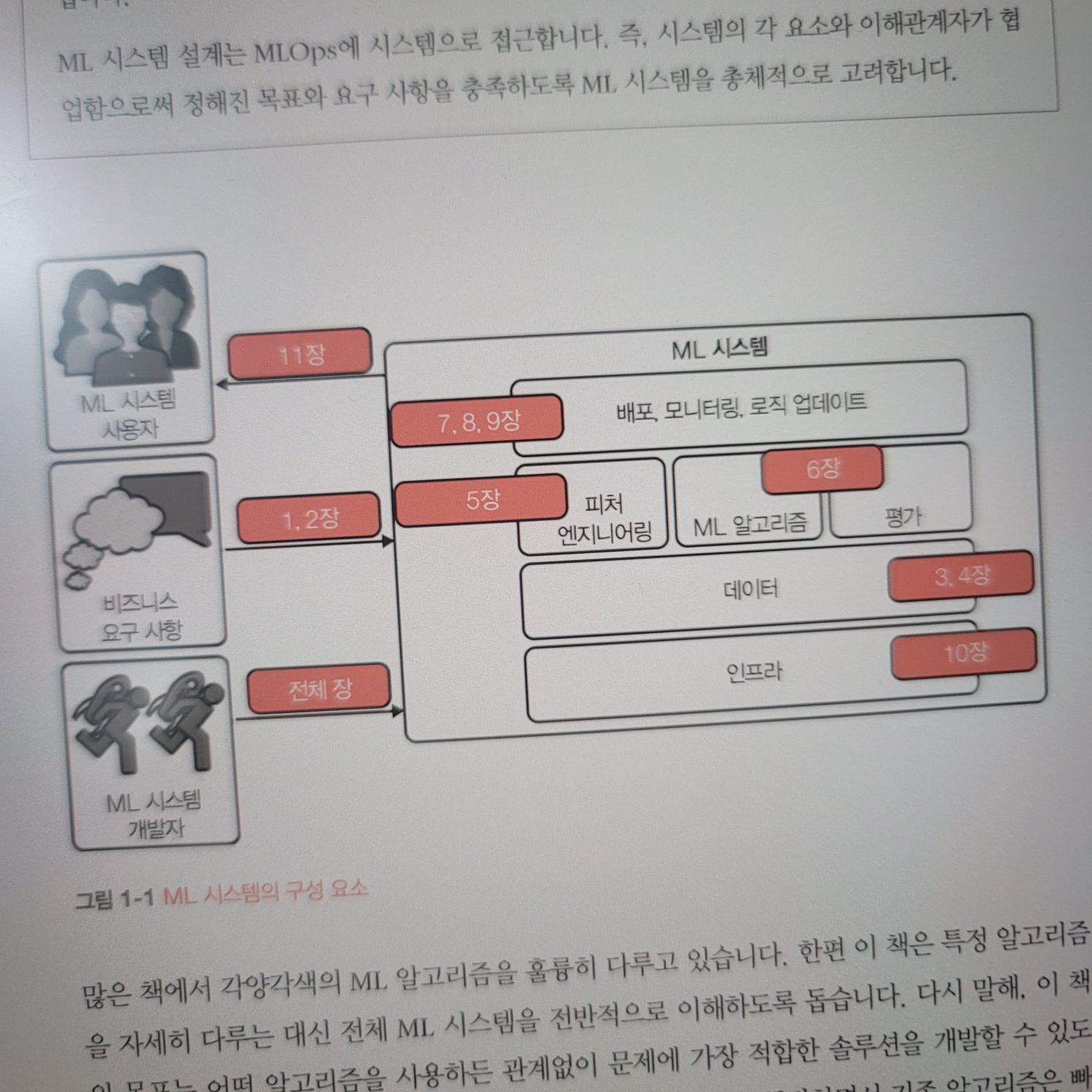
[서론]
이 책은 머신러닝 시스템을 실제로 프로덕션 환경에서 고려해야 하는 요소들을 전방위적으로 다룬다. 데이터, 피처, 모델 개발, 평가, 배포, 모니터링, 인프라 등을 종합적인 관점에서 다루며, 비즈니스 요구 사항과 이해관계자의 역할도 서술한다.
[1장 머신러닝 시스템 개요]
1장에서는 다양한 머신러닝 유스 케이스를 살펴보며 머신러닝을 적용하기에 적합한 경우와 그렇지 않은 경우를 비교한다. 또한 프로덕션용 머신러닝을 연구용 머신러닝 및 전통적인 소프트웨어와 비교하여 머신러닝 시스템 개요를 소개한다.
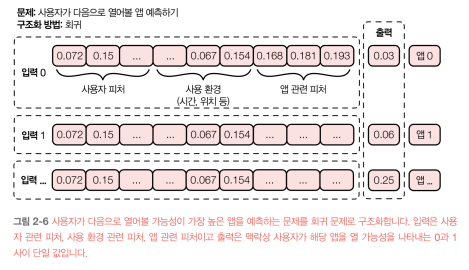
[2장 머신러닝 시스템 설계 소개]
2장에서는 비즈니스 목적에 따라 머신러닝 시스템의 요구 사항을 정하고, 이를 만족하는 시스템을 설계하기 위한 반복 프로세스를 소개한다. 또한 머신러닝 문제를 구조화하는 방법에 대해 논의한다.
[3장 데이터 엔지니어링 기초]
3장에서는 머신러닝 프로젝트에서 사용되는 다양한 데이터의 소스와 데이터를 저장하는 포맷을 살펴본다. 데이터 스토리지 엔진, 데이터 처리 유형, 데이터를 전달하는 다양한 모드 등에 대해 알아본다.
[4장 훈련 데이터]
4장에서는 양질의 훈련 데이터를 얻는 기술에 대해 다룬다. 샘플링 기술과 함께 레이블 다중성과 클래스 불균형 등 훈련 데이터 생성 시 자주 마주치는 문제를 논의한다.
[5장 피처 엔지니어링]
5장에서는 피처 엔지니어링 기법과 주요 고려 사항을 다룬다. 데이터 누수 감지 및 방지 방법과 효과적인 피처 설계에 대해 논의한다.
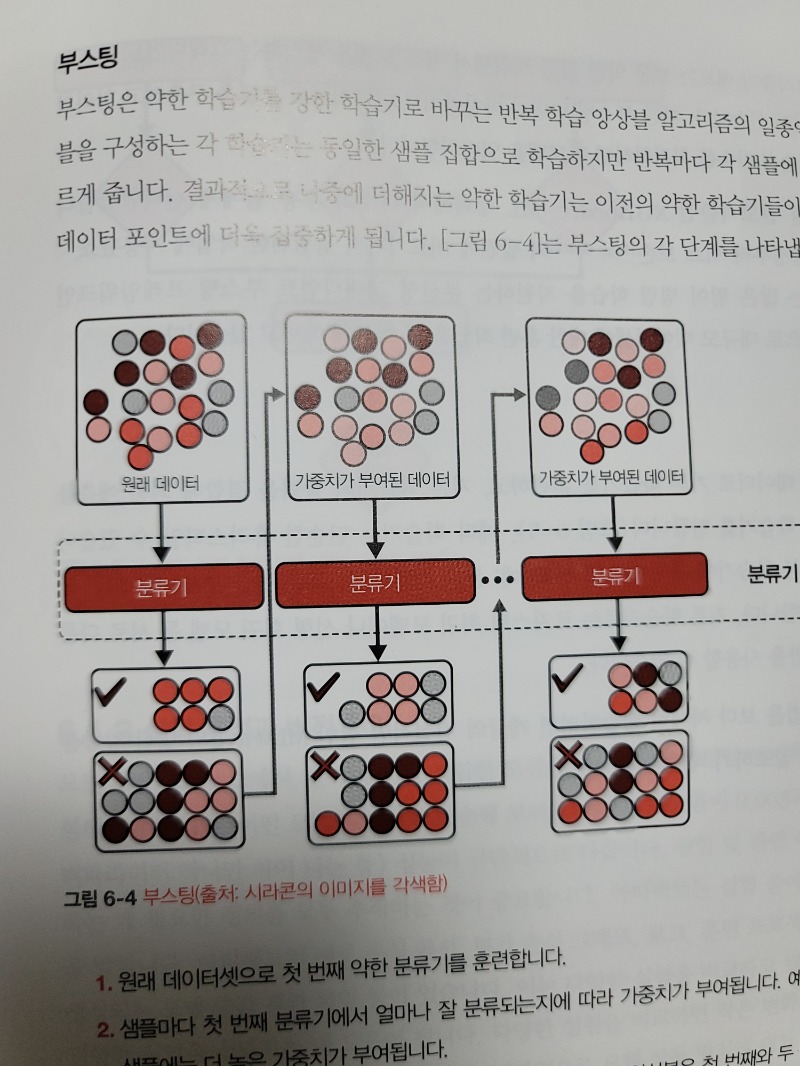
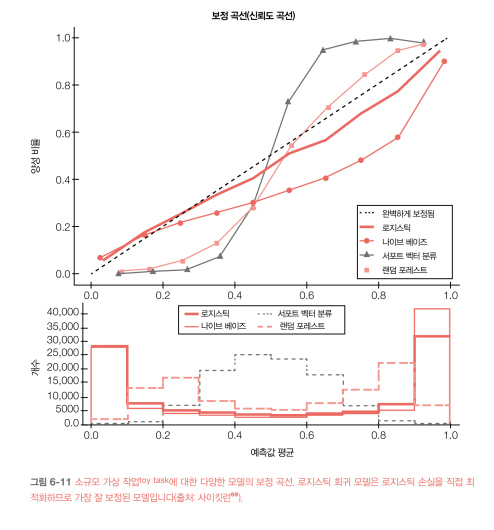
[6장 모델 개발과 오프라인 평가]
6장에서는 작업에 가장 적합한 알고리즘을 선택하는 팁과 디버깅, 실험 추적, 분산 학습, 오토ML 등 모델 개발의 다양한 측면을 다룬다.
[7장 모델 배포와 예측 서비스]
7장에서는 머신러닝 모델의 배포에 관한 통념을 살펴보고 온라인 예측과 배치 예측, 모델 압축 기술에 대해 알아본다. 또한 에지 디바이스와 클라우드에서의 모델 배포 방법을 논의한다.
[8장 데이터 분포 시프트와 모니터링]
8장에서는 프로덕션에 배포한 머신러닝 모델의 실패 원인을 다루며 데이터 분포 시프트 문제에 대해 논의한다.
[9장 연속 학습과 프로덕션 테스트]
9장에서는 데이터 분포 시프트에 대응하기 위해 머신러닝 모델을 업데이트하는 방법을 살펴본다. 연속 학습과 모델 재훈련 빈도, 프로덕션 테스트에 대해 논의한다.
[10장 MLOps를 위한 인프라와 도구]
10장에서는 MLOps를 위한 인프라 설정 방법과 네 가지 레이어(스토리지와 컴퓨팅, 자원 관리 도구, 머신러닝 플랫폼, 개발 환경)에 대해 알아본다.
[11장 머신러닝의 인간적 측면]
11장에서는 머신러닝 모델의 확률론적 특성에 따른 사용자 경험의 영향과 협업을 위한 조직 구조, 머신러닝 시스템의 사회적 영향을 다룬다.
[편집 및 번역]
칩 후옌 저자는 자신의 경험과 지식을 바탕으로 전문적이고 실용적인 내용을 전달한다. 책은 전문적으로 편집되었으며, 번역은 정확하고 자연스럽게 이루어졌다. 내용을 이해하기 쉽고 숙련된 기술 용어를 적절하게 사용하여 독자들에게 부담 없이 전달된다.
[장점]
현업에서 실제로 발생하는 문제와 상황에 대해 깊이 있는 이해를 제공한다. 다양한 측면을 다루어 주어서 현실적인 관점에서 머신러닝 시스템을 접근할 수 있다. 비즈니스 관점에서 머신러닝을 고려하고 적용하는 방법을 강조하여 실제 비즈니스 모델에 머신러닝을 효과적으로 적용할 수 있도록 도와준다. 머신러닝 시스템의 전체 생명주기를 다루어 엔드-투-엔드로 설계하고 운영하는 방법을 제시한다. 실무에 필요한 모범 사례와 경험을 공유하여 실용적인 가이드라인을 제공한다.
[단점]
초보자를 위한 입문서보다는 실무자를 대상으로 한 전문서이기 때문에 머신러닝에 대한 기본적인 지식이 부족한 독자들에게는 난이도가 높을 수 있다. 일부 내용이 기술적이고 복잡한 부분이 있어 이해하기에 어려움을 겪을 수도 있다.
[결론]
이 책은 스탠퍼드의 '머신러닝 시스템 설계' 강의를 기반으로 하며, 저자인 칩 후옌은 다양한 기업에서의 머신러닝 배포 및 운영 경험을 바탕으로 여러 가지 질문에 대한 접근법을 제시한다. 실제 비즈니스 모델에 머신러닝을 적용하고자 하는 독자들에게 유용한 지침을 제공하는 책이다. 각 장마다 실무에 필요한 내용과 관련된 예시와 모범 사례를 제시하여 머신러닝 시스템을 구축하고 운영하는 데 도움이 된다. 단점으로는 초보자를 위한 입문서보다는 전문가를 대상으로 한 책이기 때문에 기본적인 지식이 부족한 독자들에게는 난이도가 높을 수 있다. 하지만 현업에서 실제로 발생하는 문제와 도전을 다루는 이 책은 머신러닝 분야에서 실무 경험을 갖고 있는 독자들에게 많은 도움을 줄 것이다.