책소개
성공하는 머신러닝 프로젝트의 비밀
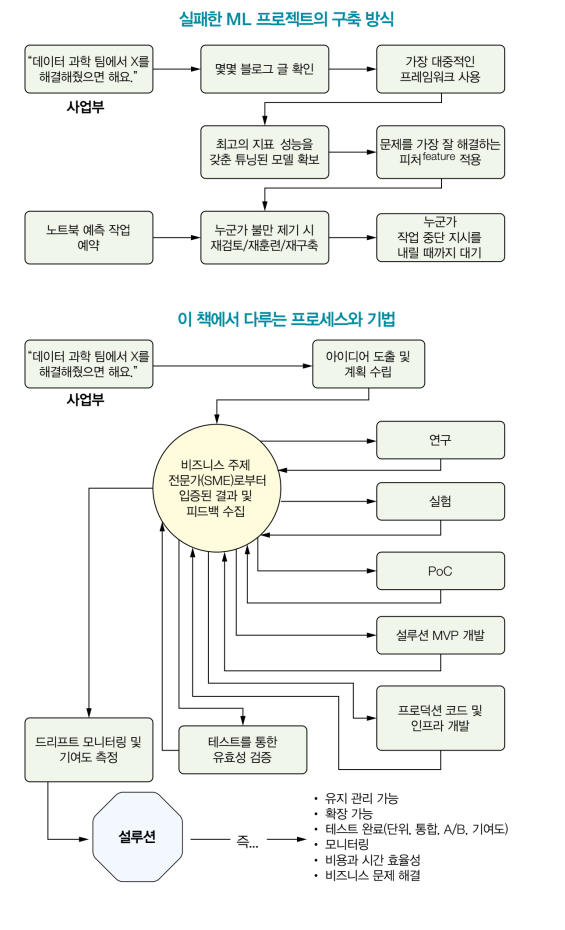
순서도와 그림으로 살펴보는 머신러닝 프로젝트 A to Z
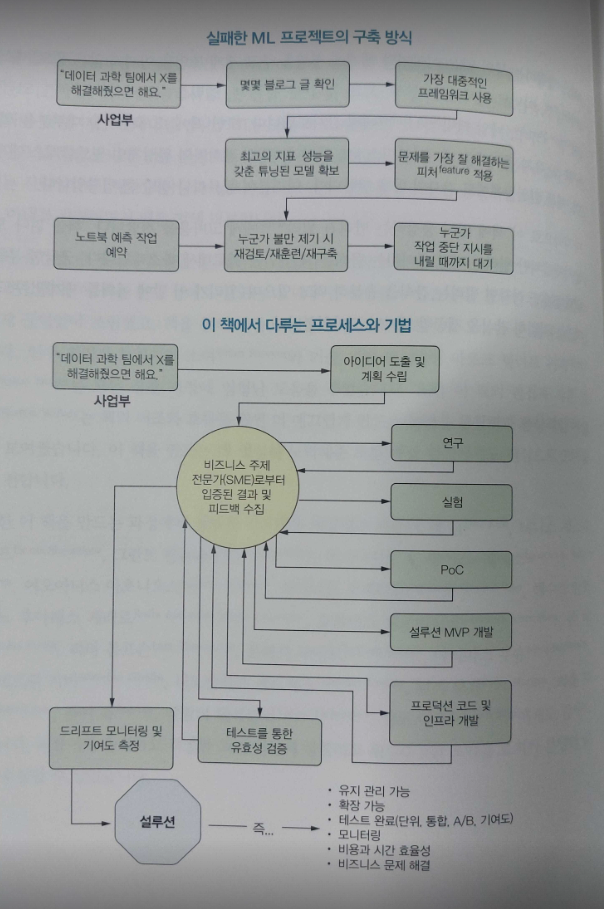
이 책은 머신러닝 엔지니어링의 기본 개념부터 머신러닝 프로젝트에 필요한 설계 원칙, 좋은 ML 코드 작성법, 프로덕션 배포 전 고려해야 할 심화 주제까지 설명합니다. 수십 년간 축적된 훌륭한 소프트웨어 엔지니어링 경험 위에 세워진 머신러닝 엔지니어링은 ML 시스템의 복원력과 적응력, 프로덕션 환경에서의 성능을 보장합니다. 프로토타입으로 테스트하고, 모듈식 설계를 통해 탄력적인 아키텍처 구축 노하우를 배우고, 협업 시 일관된 커뮤니케이션을 제공하는 소프트웨어 엔지니어링 기술을 배워보세요. 성공적인 머신러닝 프로젝트의 비밀을 여러분의 기술로 만들어 안정적인 데이터 파이프라인, 효율적인 애플리케이션 워크플로, 유지 관리 가능한 ML 모델을 직접 구축해보길 바랍니다.

저자소개

목차
[PART 1 머신러닝 엔지니어링 소개]
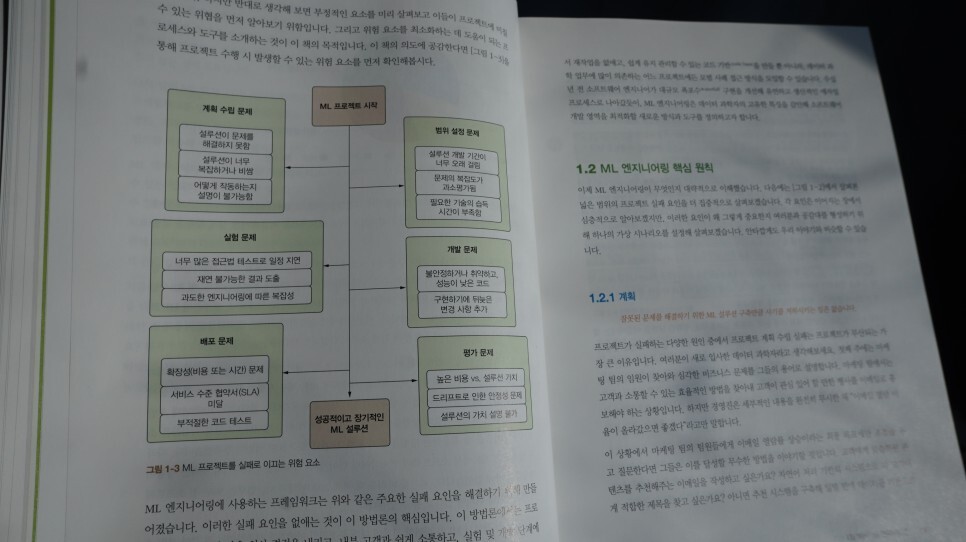
CHAPTER 1 머신러닝 엔지니어란
_1.1 ML 엔지니어링이라고 부르는 이유
_1.2 ML 엔지니어링 핵심 원칙
_1.3 ML 엔지니어링의 목표
_1.4 요약
CHAPTER 2 엔지니어링을 사용하는 데이터 과학
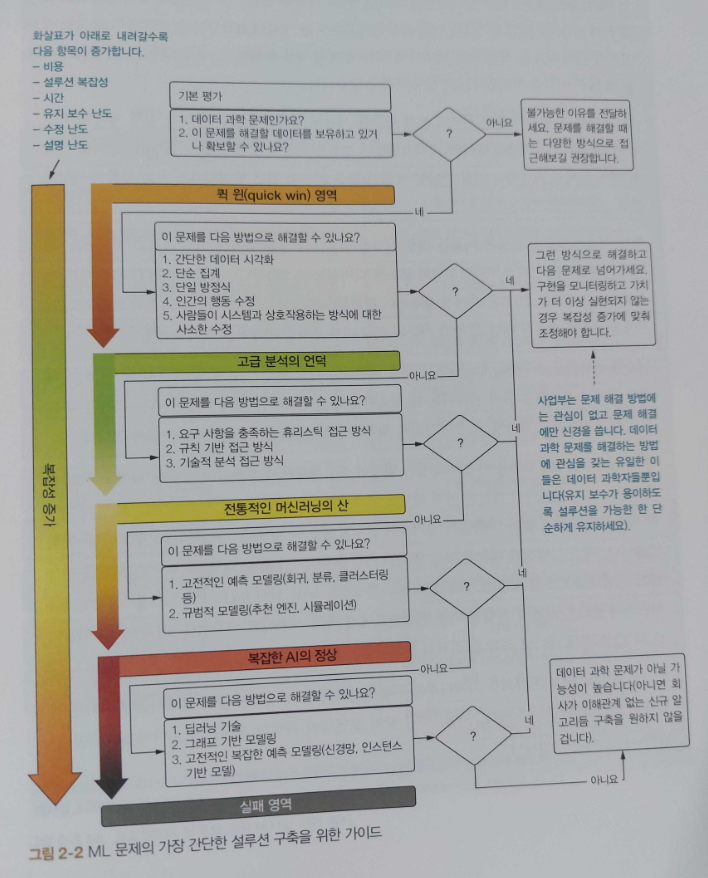
_2.1 프로젝트 성공률을 높이는 방법: 프로세스를 적용해 복잡한 전문성 강화하기
_2.2 단순한 토대의 중요성
_2.3 애자일 소프트웨어 엔지니어링의 공동 채택 원칙
_2.4 ML 엔지니어링의 기반
_2.5 요약
CHAPTER 3 프로젝트 계획 수립 및 범위 설정
_3.1 계획 수립: 무엇을 예측할까요?
_3.2 실험 범위 설정: 기대치와 제한
_3.3 요약
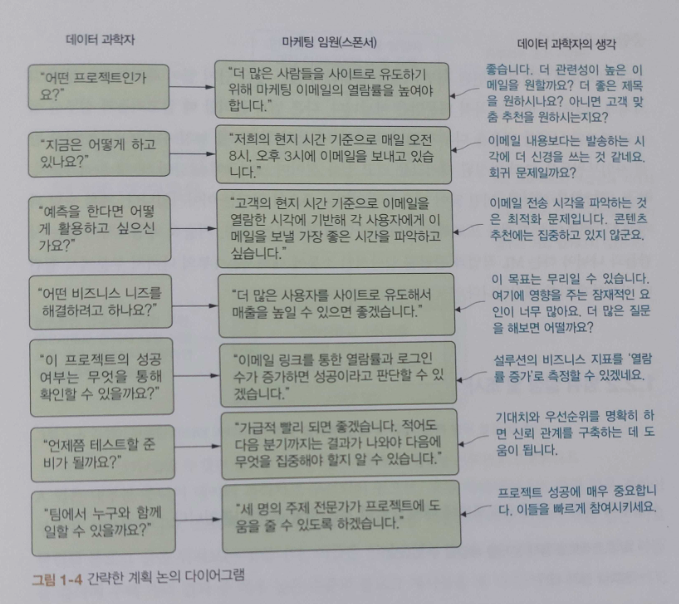
CHAPTER 4 의사소통과 프로젝트 규칙 논의
_4.1 의사소통: 문제 정의
_4.2 시간 낭비하지 않기: 크로스펑셔널 팀과의 회의
_4.3 실험 한계 설정
_4.4 비즈니스 규칙 혼돈에 대한 계획 수립
_4.5 결과에 대해 말하기
_4.6 요약
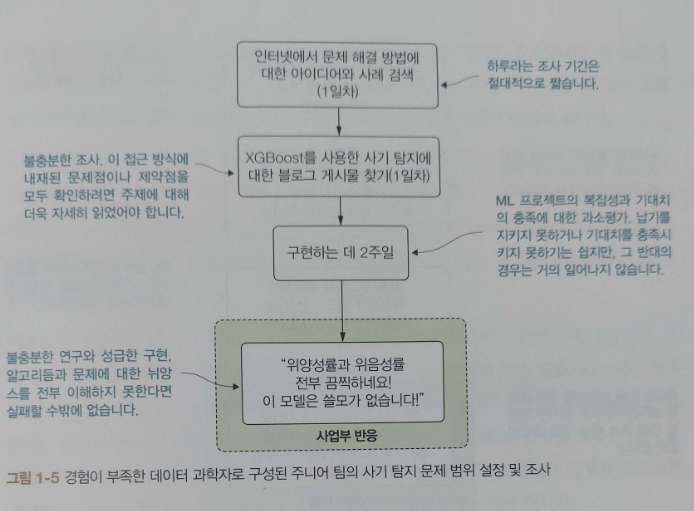
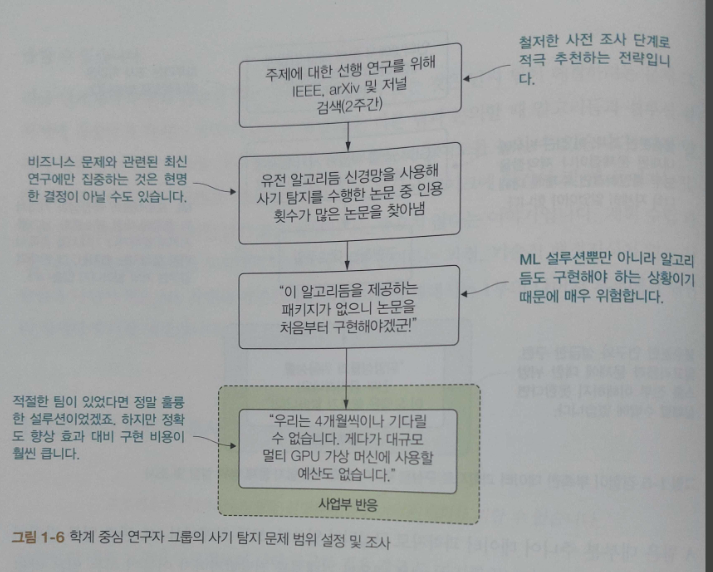
CHAPTER 5 ML 프로젝트 계획 및 연구
_5.1 실험 계획 수립
_5.2 실험 사전 준비 작업
_5.3 요약
CHAPTER 6 프로젝트 테스트 및 평가
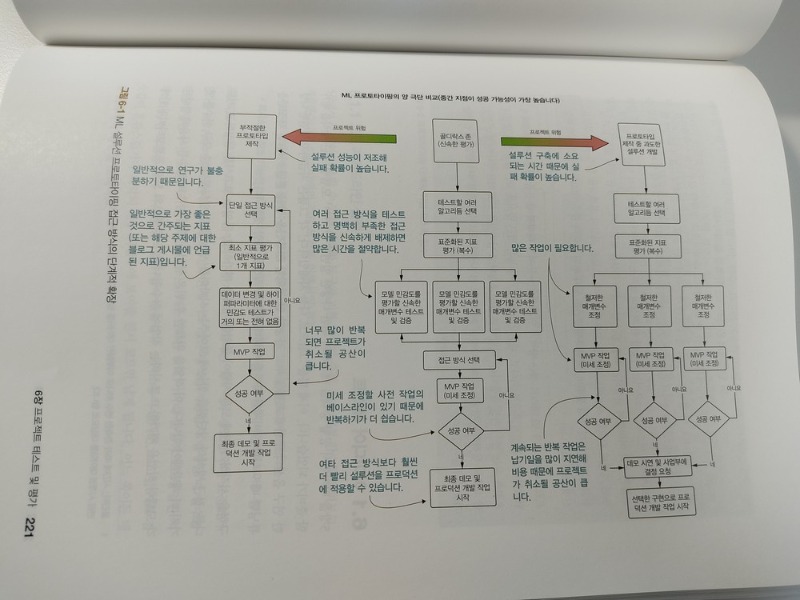
_6.1 아이디어 테스트
_6.2 가능성 좁히기
_6.3 요약
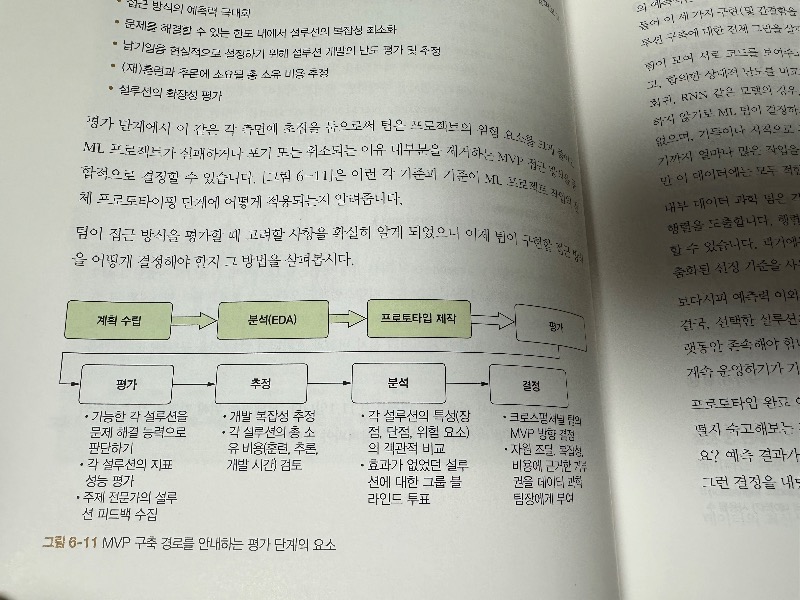
CHAPTER 7 프로토타입에서 MVP로
_7.1 튜닝: 지루한 일을 자동화합시다
_7.2 플랫폼과 팀에 적절한 기술 선택
_7.3 요약
CHAPTER 8 MLflow 및 런타임 최적화로 MVP 마무리
_8.1 로깅: 코드, 지표 및 결과
_8.2 확장성 및 동시성
_8.3 요약
[PART 2 프로덕션 준비: 유지 관리 가능한 ML 만들기]
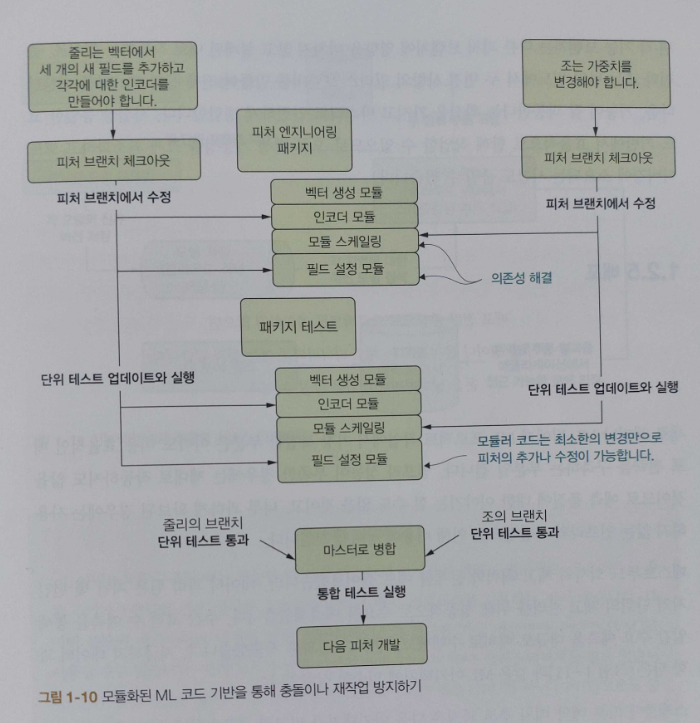
CHAPTER 9 ML 모듈화: 테스트 가능하고 읽기 쉬운 코드 작성
_9.1 모놀리식 스크립트의 개념과 나쁜 이유
_9.2 텍스트 벽으로 된 코드 디버깅
_9.3 모듈화된 ML 코드 설계
_9.4 ML에 TDD 방식 활용
_9.5 요약
CHAPTER 10 코딩 표준 및 유지 관리 가능한 ML 코드 작성
_10.1 ML 코드 스멜
_10.2 네이밍, 구조 및 코드 아키텍처
_10.3 튜플 언패킹 및 유지 관리 대안
_10.4 이슈에 눈 감기: 예외 및 기타 잘못된 관행 사용
_10.5 전역 가변 객체 사용
_10.6 과도하게 중첩된 로직
_10.7 요약
CHAPTER 11 모델의 측정과 그 중요성
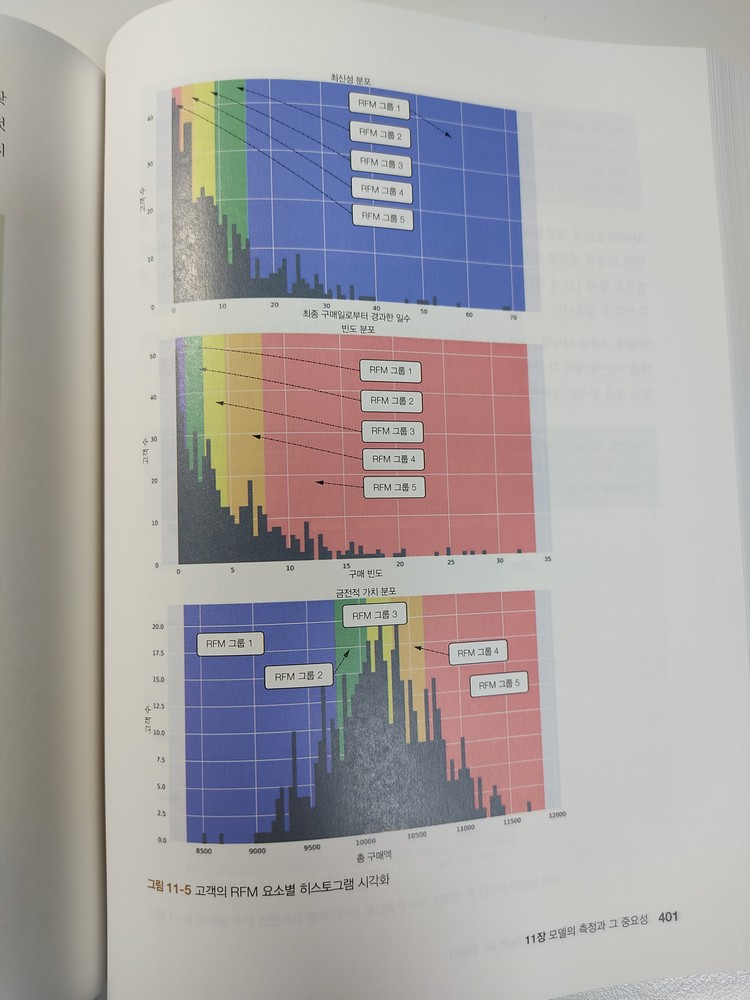
_11.1 모델의 기여도 측정
_11.2 A/B 테스트를 활용한 기여도 계산
_11.3 요약
CHAPTER 12 드리프트 주시를 통한 상승세 유지
_12.1 드리프트 감지
_12.2 드리프트 대응
_12.3 요약
CHAPTER 13 ML 개발의 오만함
_13.1 우아하게 복잡한 코드와 과도한 엔지니어링의 차이
_13.2 의도치 않은 난독화: 남이 작성한 코드를 읽을 수 있을까요?
_13.3 성급한 일반화와 최적화 그리고 자신을 드러내기 위해 사용하는 나쁜 방법
_13.4 알파 테스트와 오픈 소스 생태계의 위험성
_13.5 기술 중심 개발 vs. 설루션 중심 개발
_13.6 요약
[PART 3 프로덕션 머신러닝 코드 개발]
CHAPTER 14 프로덕션 코드 작성
_14.1 데이터를 만났나요?
_14.2 피처 모니터링
_14.3 모델 수명 주기의 나머지 항목 모니터링
_14.4 최대한 단순하게 유지하기
_14.5 프로젝트 와이어프레임 작성
_14.6 카고 컬트 ML 행위 피하기
_14.7 요약
CHAPTER 15 품질과 인수 테스트
_15.1 데이터 일관성
_15.2 콜드 스타트와 대비책
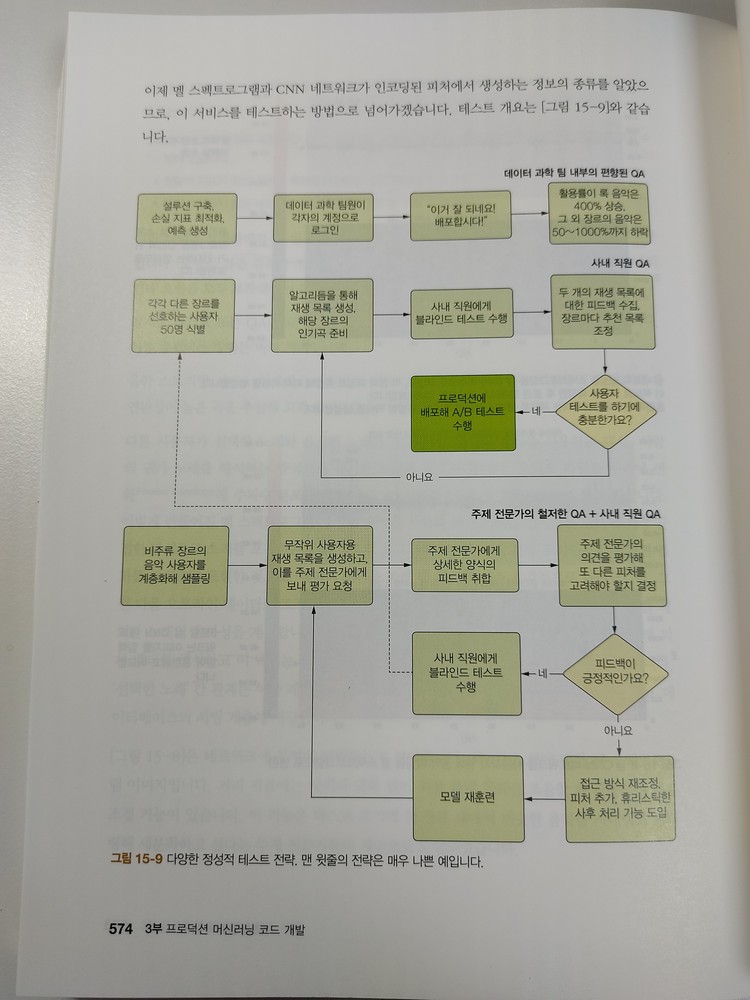
_15.3 실사용자 vs. 내부 사용자 테스트
_15.4 모델의 해석 가능성
_15.5 요약
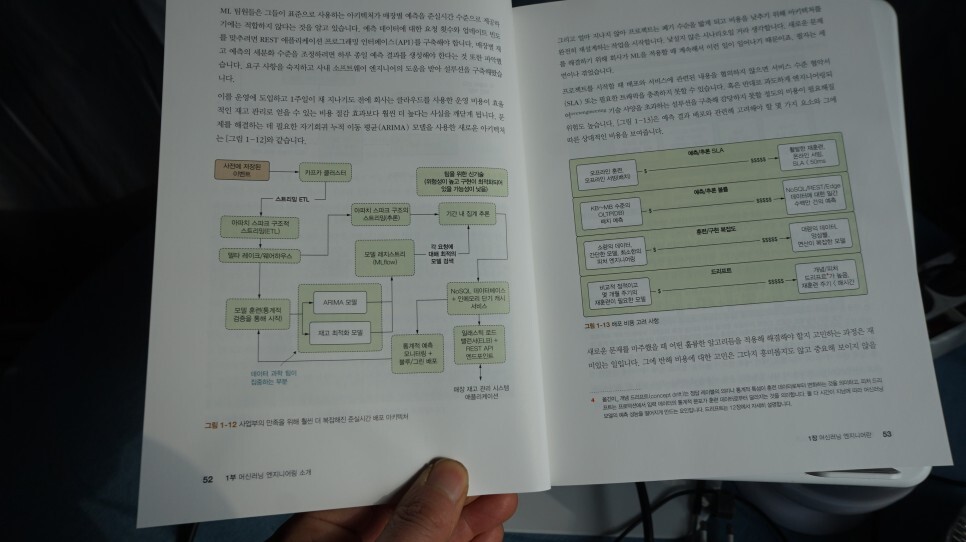
CHAPTER 16 프로덕션 인프라
_16.1 아티팩트 관리
_16.2 피처 스토어
_16.3 예측 서빙 아키텍처
_16.4 요약
[PART 4 부록]
APPENDIX A 빅오 및 런타임 성능 고려 방법
_A.1 빅오란 무엇인가요?
_A.2 예시별 복잡도
_A.3 의사 결정 트리 복잡도 분석
_A.4 일반적인 ML 알고리듬 복잡도
APPENDIX B 개발 환경 설정
_B.1 깔끔한 실험 환경의 예
_B.2 컨테이너를 활용한 의존성 지옥 대응
_B.3 컨테이너 기반의 깨끗한 실험 환경 만들기
출판사리뷰
머신러닝 프로젝트 종사자 필독서!
다양한 예시, 이해를 돕는 순서도, 좋은 코드 작성법, 함정 회피법까지
머신러닝 개발 현장에서 터득한 노하우 대방출
프로젝트에 머신러닝을 도입해 프로덕션 수준으로 끌어올리기까지는 수많은 시행착오가 필요합니다. 그 시행착오 과정에서 길을 이끌어주는 훌륭한 가이드가 있다면 얼마나 든든할까요? 저자 벤 윌슨은 수많은 머신러닝 프로젝트를 직접 경험하며 온몸으로 터득한 노하우를 여러분에게 선보입니다. 비즈니스에 머신러닝을 도입할 때 마주하기 쉬운 함정을 피하는 방법과 일을 두 번 하지 않게 하는 계획 수립 전략, 협업 부서와의 현명한 소통법, 장기적으로 유지 관리 가능한 프로젝트 구현 방법, 배포 시 유념해야 할 사항들까지 머신러닝 프로젝트 설계 전반에 걸친 유용한 내용을 소개합니다. 이 책은 머신러닝 개발 현장에서 고군분투하고 있는 엔지니어뿐 아니라 데이터 과학자, 소프트웨어 아키텍트 등 머신러닝 프로젝트에 발을 담고 있는 모든 분에게 유용합니다. 이 책을 읽고 나면 각자의 역할을 더 잘 이해하고 업무를 더 효율적으로 요청하고 수행할 수 있을 것입니다.
주요 내용
장별 내용
대상 독자
오탈자 등록