책소개
데이터 분석을 배우는 가장 완벽한 방법
파이썬 라이브러리 사용법부터 실제 데이터를 활용한 실습까지
믿고 보는 파이썬 데이터 분석 대표 도서가 3판으로 돌아왔다. 파이썬 판다스 프로젝트 창시자인 웨스 맥키니가 직접 설명하는 파이썬 라이브러리 사용법은 실용적이고 현대적이다. 파이썬과 판다스 최신 버전을 기준으로 내용을 업데이트했고 다양한 사례를 살펴보며 데이터 분석 문제를 효과적으로 해결하는 방법을 알아본다.
판다스, 넘파이, IPython, 맷플롯립, 주피터 등 다양한 파이썬 라이브러리를 소개하고 새로운 기능뿐만 아니라 메모리 사용량을 줄이고 성능을 개선하는 고급 사용법까지 다룬다. 또한 모델링 도구인 statsmodels와 사이킷런 라이브러리도 소개한다. 신생아 이름 통계 자료, 대선 데이터베이스 등 실제 데이터로 실습하며 데이터에 적합한 도구를 선택하고 효과적으로 분석하는 전문가로 거듭나보자.
저자소개

목차
CHAPTER 1 시작하기 전에
1.1 다루는 내용
1.2 데이터 분석에 파이썬을 사용하는 이유
1.3 필수 파이썬 라이브러리
1.4 설치 및 설정
1.5 커뮤니티와 콘퍼런스
1.6 이 책을 살펴보는 방법
CHAPTER 2 파이썬 기초, Ipython과 주피터 노트북
2.1 파이썬 인터프리터
2.2. IPython 기초
2.3 파이썬 기초
2.4 마치며
CHAPTER 3 내장 자료구조, 함수, 파일
3.1 자료구조와 순차 자료형
3.2 함수
3.3 파일과 운영체제
3.4 마치며
CHAPTER 4 넘파이 기본: 배열과 벡터 연산
4.1 다차원 배열 객체 ndarray
4.2 난수 생성
4.3 유니버설 함수: 배열의 각 원소를 빠르게 처리하는 함수
4.4 배열을 이용한 배열 기반 프로그래밍
4.5 배열 데이터의 파일 입출력
4.6 선형대수
4.7 계단 오르내리기 예제
4.8 마치며
CHAPTER 5 판다스 시작하기
5.1 판다스 자료구조 소개
5.2 핵심 기능
5.3 기술 통계 계산과 요약
5.4 마치며
CHAPTER 6 데이터 로딩과 저장, 파일 형식
6.1 텍스트 파일에서 데이터를 읽고 쓰는 법
6.2 이진 데이터 형식
6.3 웹 API와 함께 사용하기
6.4 데이터베이스와 함께 사용하기
6.5 마치며
CHAPTER 7 데이터 정제 및 준비
7.1 누락된 데이터 처리하기
7.2 데이터 변형
7.3 확장 데이터 유형
7.4 문자열 다루기
7.5 범주형 데이터
7.6 마치며
CHAPTER 8 데이터 준비하기: 조인, 병합, 변형
8.1 계층적 색인
8.2 데이터 합치기
8.3 재구성과 피벗
8.4 마치며
CHAPTER 9 그래프와 시각화
9.1 맷플롯립 API 간략하게 살펴보기
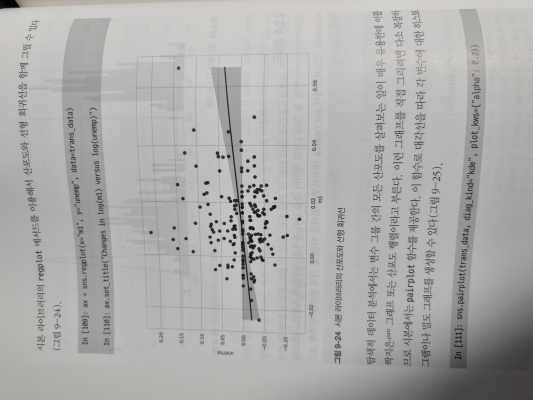
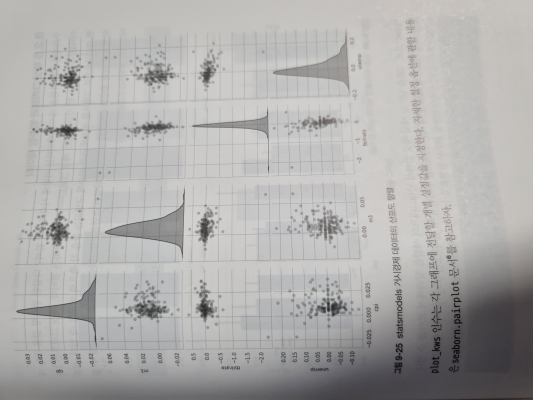
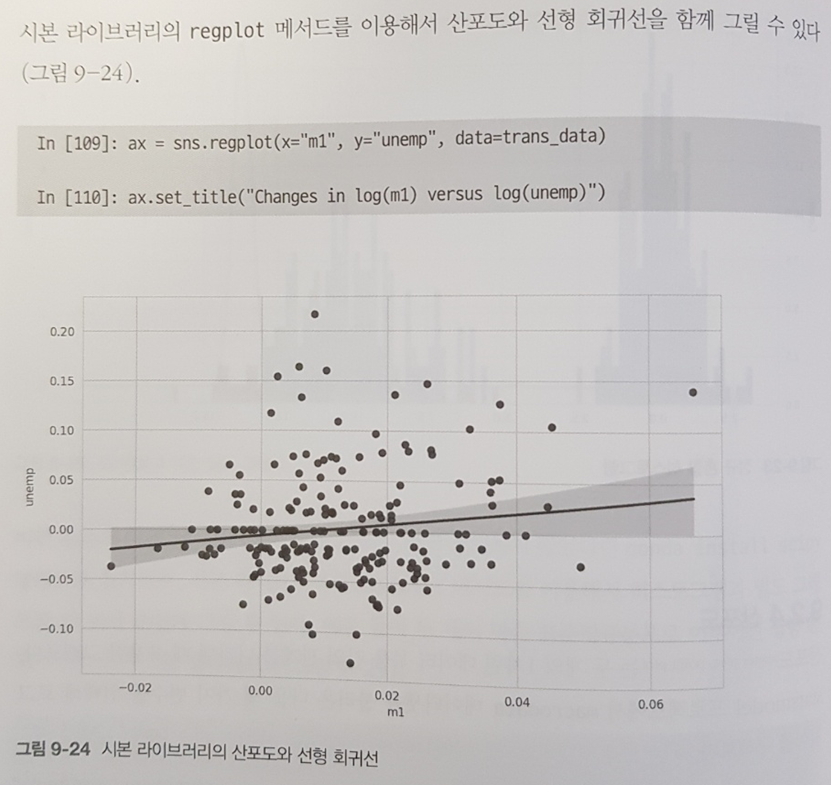
9.2 판다스에서 시본으로 그래프 그리기
9.3 다른 파이썬 시각화 도구
9.4 마치며
CHAPTER 10 데이터 집계와 그룹 연산
10.1 그룹 연산에 대한 고찰
10.2 데이터 집계
10.3 apply 메서드: 일반적인 분리-적용-병합
10.4 그룹 변환과 래핑되지 않은 groupby
10.5 피벗 테이블과 교차표
10.6 마치며
CHAPTER 11 시계열
11.1 날짜, 시간 자료형과 도구
11.2 시계열 기초
11.3 날짜 범위, 빈도, 이동
11.4 시간대 다루기
11.5 기간과 기간 연산
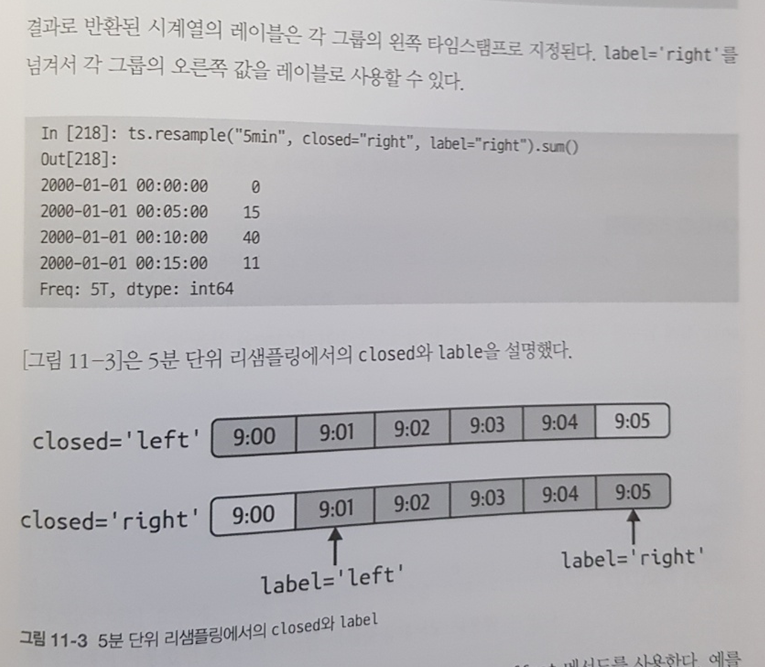
11.6 리샘플링과 빈도 변환
11.7 이동창 함수
11.8 마치며
CHAPTER 12 파이썬 모델링 라이브러리
12.1 판다스와 모델 코드의 인터페이스
12.2 patsy로 모델 생성하기
12.3 statsmodels 소개
12.4 사이킷런 소개
12.5 마치며
CHAPTER 13 데이터 분석 예제
13.1 Bitly의 1.USA.gov 데이터
13.2 무비렌즈의 영화 평점 데이터
13.3 신생아 이름
13.4 미국 농무부 영양소 정보
13.5 2012년 연방선거관리위원회 데이터베이스
13.6 마치며
APPENDIX A 고급 넘파이
A.1 ndarray 객체 구조
A.2 고급 배열 조작 기법
A.3 브로드캐스팅
A.4 고급 ufunc 사용법
A.5 구조화된 배열과 레코드 배열
A.6 정렬 더 알아보기
A.7 넘바를 이용해 빠른 넘파이 함수 작성하기
A.8 고급 배열 입출력
A.9 유용한 성능 팁
APPENDIX B IPython 시스템 더 알아보기
B.1 터미널 키보드 단축키
B.2 매직 명령어
B.3 명령어 히스토리 사용하기
B.4 운영체제와 함께 사용하기
B.5 소프트웨어 개발 도구
B.6 IPython을 이용한 생산적인 코드 개발 팁
B.7 IPython 고급 기능
B.8 마치며
출판사리뷰
판다스 핵심 개발자의 데이터 분석 라이브러리 사용 설명서
2013년 수정 보완판으로 출간되어 2019년 2판까지 꾸준히 국내 독자에게 사랑받아온 [파이썬 라이브러리를 활용한 데이터 분석]이 3판으로 돌아왔다. 지난 10년 동안 파이썬은 데이터 과학, 머신러닝, 딥러닝에 이르기까지 수많은 분야에서 널리 사용하는 인기 있는 언어로 굳건히 자리 잡았고, 사용자를 위해 꾸준히 업데이트되었다. 3판은 최신 버전의 파이썬, 넘파이, 판다스 및 기타 프로젝트의 변경 사항에 맞춰 책 내용을 다듬었다. 이 책이 대학에서는 교재로, 현업에서는 참고 도서로 많이 사용되는 만큼 이후 몇 년까지도 유효한 내용을 담기 위해 심혈을 기울였다. 파이썬으로 데이터를 다뤄야 하는 모든 이에게 귀중한 도서가 되기를 바란다.
3판에서 달라진 점
- 파이썬 3.11, 판다스 2.0 기반으로 코드 업데이트
- 넘파이 1.23, 주피터 최신 버전 반영
- 새로운 내용 추가
- 범주형 데이터 자료형
- 데이터 그룹 변환과 래핑되지 않은 groupby
- IPython의 매직 명령어와 명령어 히스토리 사용법
이 책은 파이썬으로 데이터를 다루는 다양하고 기본적인 방법을 소개한다. 파이썬 프로그래밍 언어 기초와 데이터 분석 문제를 효율적으로 해결하는 데 도움이 되는 라이브러리를 다룬다. 책의 제목에 ‘데이터 분석’이 들어가 있긴 하지만 데이터 분석 방법론보다는 파이썬 프로그래밍, 라이브러리, 도구에 집중해 설명한다.
대상 독자
- 데이터 분석 실무를 맡게 된 데이터 엔지니어, 데이터 과학자, 머신러닝 엔지니어, 통계 전문가
- 파이썬 대표 라이브러리로 데이터를 분석해보고 싶은 IT 관련 학부생
주요 내용
- 넘파이 기초와 고급 기능 사용법
- 판다스로 데이터 로딩, 정제, 조인, 변형하기
- 맷플롯립으로 유용한 시각화 만들기
- 판다스 groupby 기능으로 데이터를 나누고 요약하기
- 규칙적이거나 불규칙적인 시계열 데이터 분석 및 조작하기
- 실제 데이터를 살펴보며 분석 문제 해결법 알아보기
옮긴이의 말
인쇄기가 세 번째 한국어판을 막 찍어내려던 순간 판다스 2.0이 릴리스되면서 10년 전 초판을 번역했을 때 기억이 떠올랐다. 판다스 0.14 버전으로 쓰인 책을 번역하던 도중 계속 새로운 버전이 나오면서 많은 부분을 고치는 과정이 말도 못 할 정도로 힘들었는데, 이번에는 판다스 2.0을 설치하고 예제 코드를 다시 검토해 저자에게 PR을 보내고, 확인 요청까지 하는 과정이 다행히 초판 작업 때만큼 힘들지는 않았다. :)
판다스도 오랫동안 함께 사용할 수 있는 안정적인 라이브러리가 되었고 이 책 또한 저자의 바람대로 오래 두고 볼 수 있게 되었다. 2판이 도움이 되었다면 파이썬을 활용해 데이터를 들여다보고자 하는 지인들에게 망설임 없이 추천해도 좋을 책이다.
오탈자 등록