






































주변에서 판다스 책을 추천해 달라는 얘기를 들으면 이 책을 가장 우선으로 추천하곤 했다. 제목은 파이썬 라이브러리를 활용한 데이터 분석이지만 이 책 만큼 판다스를 잘 다루고 있는 책은 드물 것이다. 왜냐면 이 책은 판다스 라이브러리를 개발한 웨스매키니가 직접 쓴 책이기 때문이다.
수학을 전공한 웨스매키니는 R에서 영향을 받아 판다스 라이브러리를 만들었다고 한다. 또, 증권사에서 퀀트로 일했기 때문에 행과열로 된 데이터 뿐만 아니라 시계열 데이터를 다루기도 좋다. 그리고 내부적으로 Numpy 라이브러리를 수치계산 라이브러리로 사용하고 있기 때문에 계산도 빠른 편이다. 데이터분석, 전처리, 피처엔지니어링, 시각화, 시계열 분석, 업무 자동화 등 판다스는 다양한 분야에서 활용되고 있다.
또, 비전공자나 비개발자들이 프로그래밍을 배우고 싶다고 뭐부터 배우면 좋을지 물어보면 판다스 라이브러리를 가장 많이 추천한다.
엑셀은 전공이나 도메인에 무관하게 사용되고 있다. 그런데 엑셀의 치명적인 단점이 대용량 데이터를 다루기에 적합하지 않다는 것이다. 100만줄 이상의 엑셀파일을 불러온 경험이 있는 사람이라 면 그 데이터를 로드하는 것도 힘들지만 컬럼하나를 추가하거나 간단한 수식을 추가하기 위해서도 우리의 많은 인내심을 요구하게 된다.
그런데 같은 파일을 판다스로 읽어온다면 내 컴퓨터의 메모리가 허락하는 한도내에서 데이터를 로드해서 전처리를 자유롭게 할 수 있고 파이썬 스크립트를 작성해 놓으면 매달 혹은 매주, 매일 >반복되는 업무에서 파일위치만 변경해 주면 반복된 작업을 엑셀만을 사용하는 것보다 간편하게 처리할 수 있다.
이 책의 초판이 출판된지 시간이 많이 지나서 2판이 나왔으면 좋겠다는 생각을 종종 해왔는데 이렇게 2판이 출판되었을 때 반가운 마음이 들었다.
또, 이 책은 판다스 뿐만 아니라 책의 초반부를 파이썬 기초 문법에 할애하고 있다. 이 책을 통해 파이썬을 처음 배우는 초심자라면 꼭 필요한 파이썬 기초도 함께 배울 수 있다.

책 표지 - 만약 판다곰이 판다스와 관계가 있다면 표지가 판다곰이지 않았을까 싶지만, 판다곰과 Pandas는 아무런 상관이 없기 때문에 표지에도 판다곰이 등장하지 않는다.

2판이 나오며 개선된 내용이 정리되어 있다.

목차 - bit.ly의 usa.gov 데이터로 실사례를 분석해 볼 수 있다. 타임존, 운영체제별 데이터를 집계해보는 예제가 있다.
MovieLens의 데이터는 영화 평점 데이터를 텍스트와 함께 분석해 본다.
신생아 이름은 1800년대부터 태어난 신생아의 이름을 분석해 보며, 특정 이름이 특정 시기에 유행을 하고 있다는 것을 볼 수 있다.
이 외에도 미국 농무부의 영양소 정보라든지, 연방선거관리 위원회 데이터베이스를 볼 수 있다.

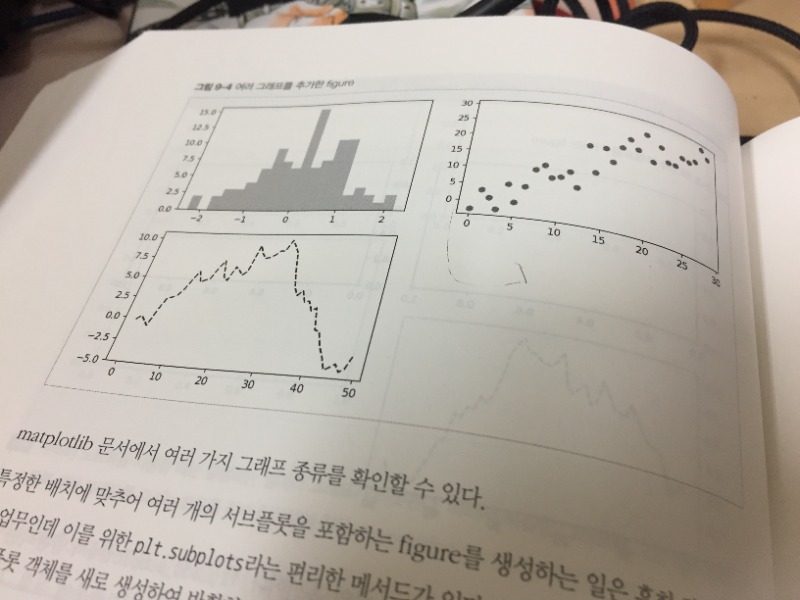
matplotlib을 pandas 를 통해 더 간단하게 사용할 수 있는 코드를 안내한다.

유행하는 이름의 트랜드를 시각화로 확인해 볼 수 있다.
그리고 아래의 URL에 소스코드도 모두 공개가 되어 있다. 2판이 업데이트 되며, 2nd-edition 이라는 브랜치가 추가되었다.
아래의 링크에서 colab으로 직접 실습이 가능하다. https://colab.research.google.com/github/wesm/pydata-book/blob/2nd-edition/ch02.ipynb
github 소스코드는 아래 링크에서 확인해 볼 수 있다. wesm/pydata-book: Materials and IPython notebooks for “Python for Data Analysis” by Wes McKinney, published by O’Reilly Media







