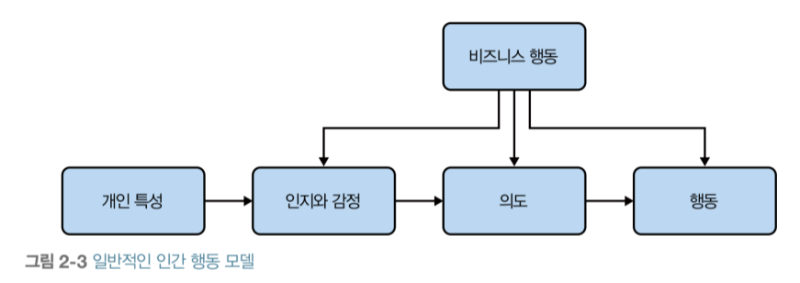
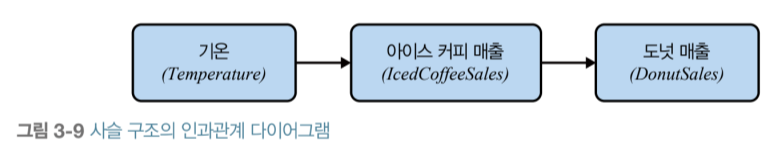
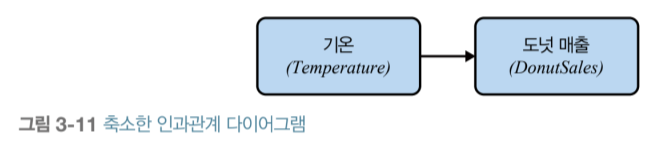
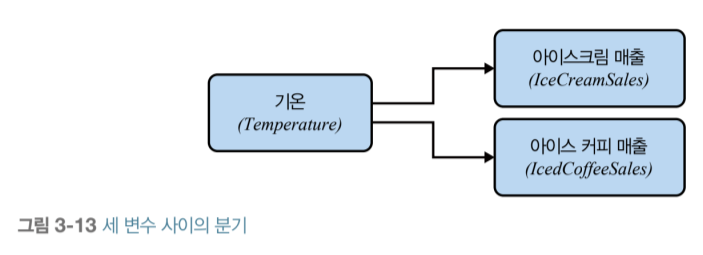
■ 행동 데이터 분석 읽고 주저리
.
R과 파이썬으로 시작하는 행동 데이터 분석 가이드
전세계 행동과학 저문가 필독서
고객 중심 데이터 분석으로 최적의 비즈니스 전략 세우기
.
지은이 : #플로랑뷔송
옮긴이 : #시진
이메일 : ask@hanbit.co.kr
출판사 : #한빛미디어
.
#행동데이터분석 #행동데이터 #행동과학 #데이터분석 #비즈니스전략
.
#책을펴면서
이전에 #파이썬 책을 본 경험이 있었는데~ 그 프로그램으로 행동 데이터를 분석하는 방법, 가이드에 대해서 배웠으면 좋겠다는 생각담아 책을 펴본다. 고객 중심 데이터 분석 이라는 부분은 최근 다양하게 변해가는 소비자의 트렌드를 잘 이해하고 분석하는데 도움을 주고, 거기에 그 결과에 따른, 분석에 따른 비즈니스 전략을 수립하는데도 도움이될 수 있는 내용을 발견해 나가기를 바래본다.
.
‘ #데이터 는 새로운 석유다 라는 말처럼 데이터는 하나의 자원으로 자리잡았으며 데이터를 처리하는 알고리즘은 경제를 발전시키는 일종의 새로운 엔진이라고 말할 수 있습니다’
--10페이지에서--
.
‘교란변수가 있는 환경에서 회귀모델의 계수를 인과관계로 해석하면 잘못된 결론을 내리게 됩니다’
--40페이지에서--
.
‘사공이 많으면 배가 산으로 가듯이 변수가 너무 많으면 문제가 될 수 있습니다’
--41페이지에서--
.
‘사람의 마음을 변호시키는 것은 그 사람의 행동에 영향을 미치는 것과는 다르며, 그 반대도 마찬가지입니다’
--50페이지에서--
.
‘비유를 하자면 누군가가 어떤 이야기를 했을 때 행동 과학자는 그 이야기가 믿을만하다고 확인할 때까지 의심을 하고 UX 연구원은 반대로 그 이야기가 틀렸다는 점을 확인할 때까지 사실로 믿습니다’
--54페이지에서--
.
‘광고, 마케팅과 협상의 목표는 누군가의 의도에 영향을 미치는 것입니다’
--56페이지에서--
.
‘비즈니스에서는 의도를 달성하는 것을 방해하는 장애물을 표현할 때 페인포인트 (pain point)라는 용어를 사용합니다. 고객의 페인 포인트를 해결하는 방법에 집중하다보면 원하는 목표를 이룰 수 있는 길을 찾을 것입니다’
--56페이지에서--
.
‘가치있는 결론을 얻으려면 먼저 주어진 정보로부터 의미를 찾아내야 합니다’
--64페이지에서--
.
‘상관관계는 인과관계가 아니기 때문에 더 이상 아무것도 추론할 수 없습니다.’
--81페이지에서--
.
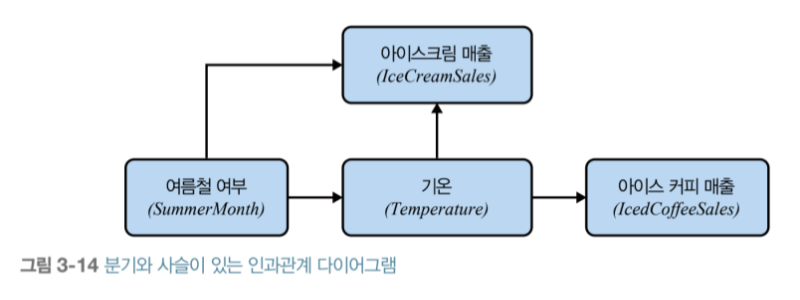
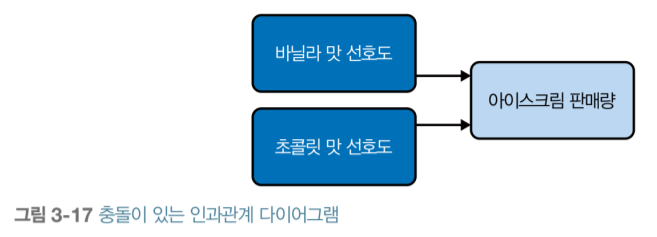
‘세상ㅇ[ 원인이 단 하나인 경우는 거의 없습니다. 2개 이상의 변수가 동일한 결과를 낳으면 관계는 충돌이 생깁니다.’
--88페이지에서--
.
‘ #대체효과 = 경제학 이론에서 아주 중요한 개념입니다. 고객은 제품의 가용성, 가격, 고객의 다양한 욕구에 따라 제품을 다른 제품으로 대체 할 수 있습니다’
--94페이지에서--
.
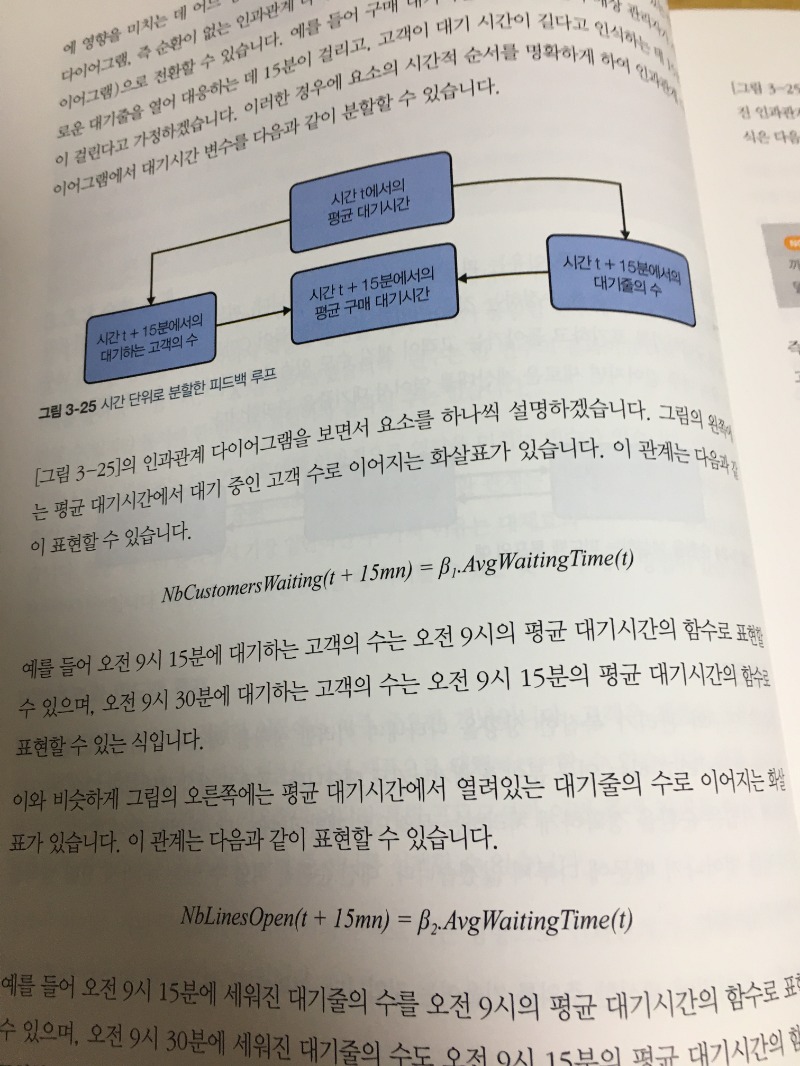
‘ #피드백루프 = 사람이 환경의 변화에 반응하여 행동을 수정하는 것~’
--95페이지에서--
.
‘이책의 목표는 한 변수가 다른 변수에 미치는 영향을 측정하는 것입니다’
--101페이지에서--
.
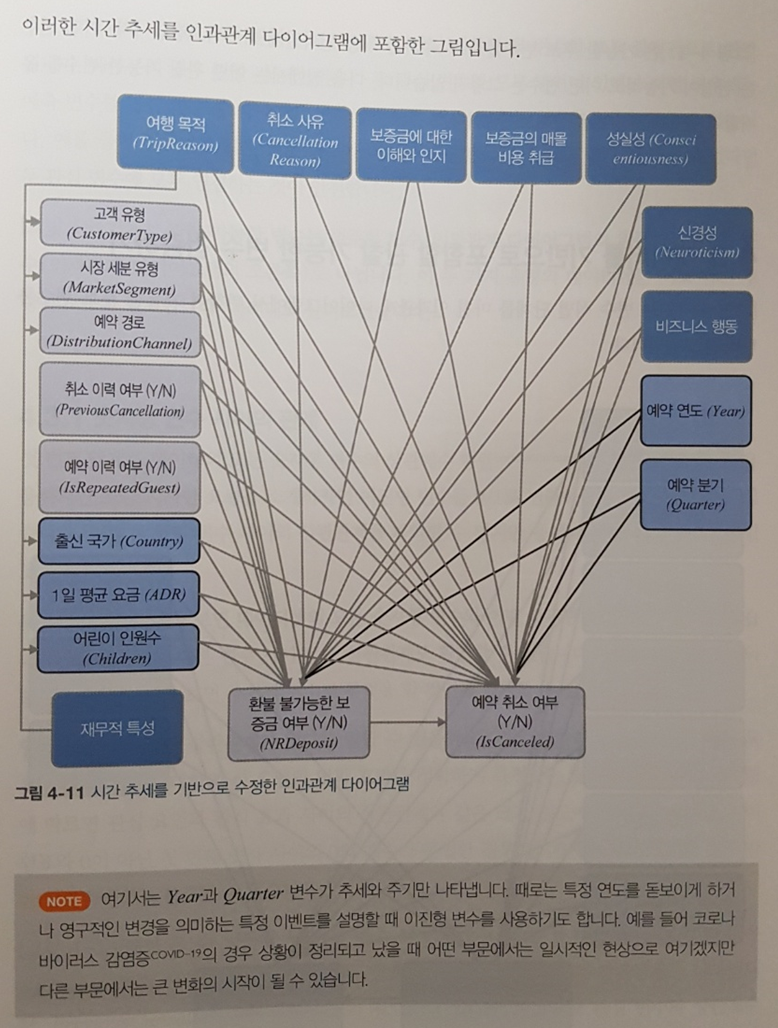
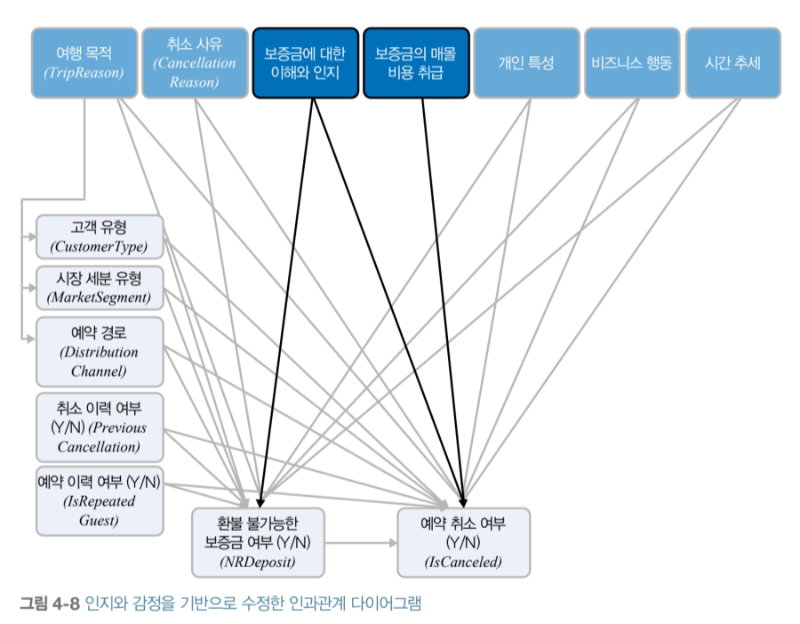
‘두 관심변수의 공동 요인을 제대로 이해하지 못하면 상황을 잚소 해석하게 되고 관심 요인에 대한 회귀 계수는 편향됩니다 (중략) 따라서 어떤 변수를 포함하고 어떤 변수를 포함하지 않을지 결정하는 것은 데이터 분석 또는 더 나아가 인과적 사고방식의 교란을 해소하는 가장 중요한 문제~’
--131페이지에서--
.
‘분석 결과가 비즈니스 파트너에게 동일한 의미를 가진다면 결측 데이터를 삭제할 수 있습니다’
--157페이지에서--
.
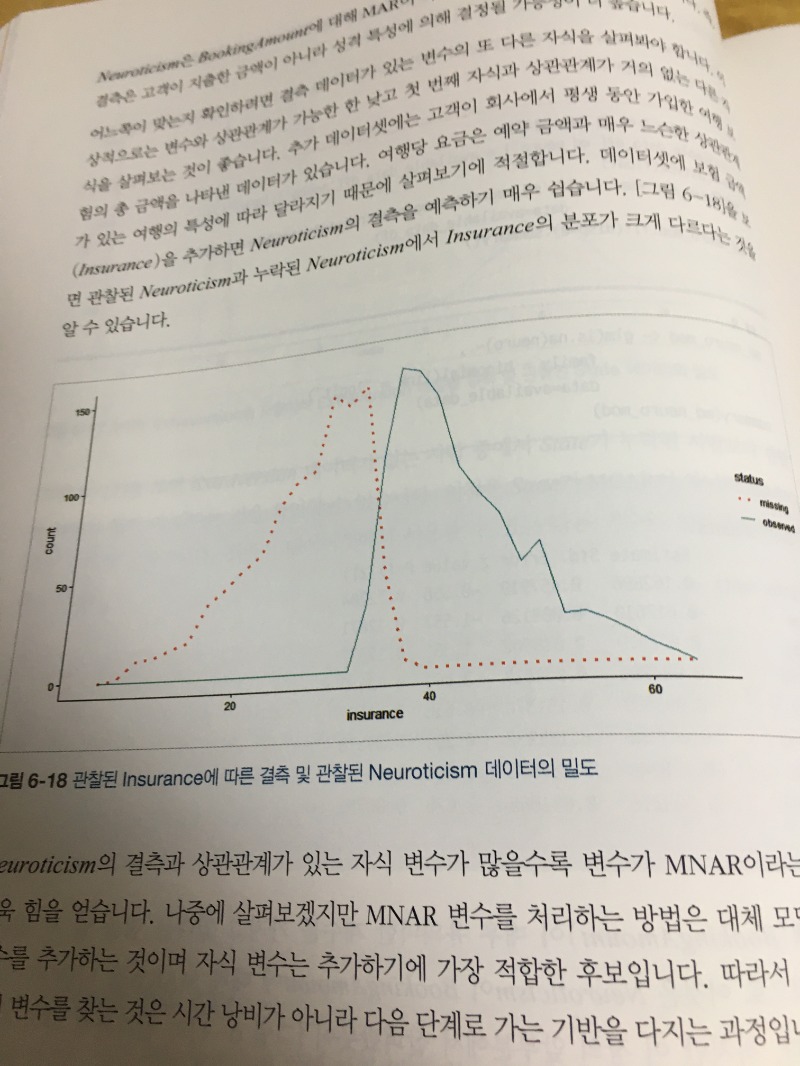
‘결측의 상관관계가 높은 변수가 있다면 이것은 한 변수의 누락이 다른 변수의 누락을 의미한다는 것을 의미합니다’
--158페이지에서--
.
‘관찰되지 않은 변수는 #잠재변수 라고도하며 이론상으로는 접근 가능할 수도 있지만 실제로는 가지고 있지 않은 정보를 말합니다’
--164페이지에서--
.
‘결측의 유영을 신중하게 분류했을 때 시간은 더 걸리겠지만 편향이 생기지 않는다는 것~’
--169페이지에서--
.
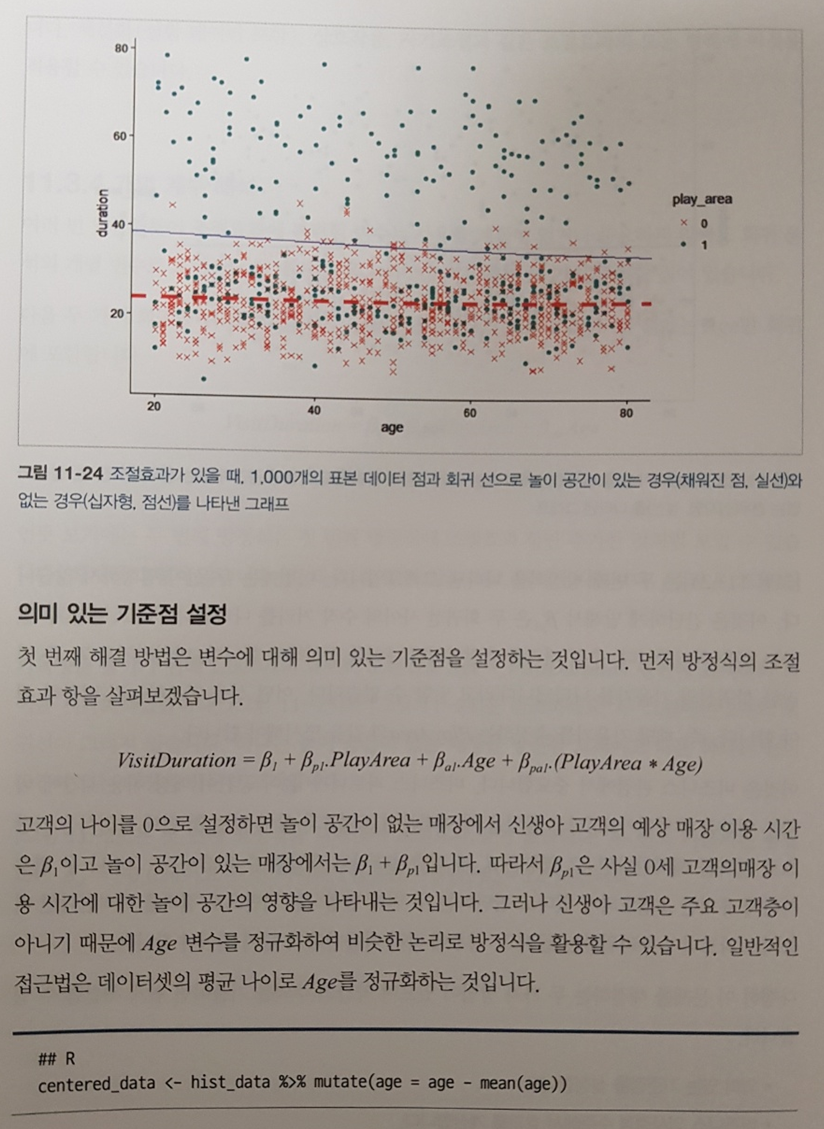
‘특히 행동 및 자연과학에서는 숫자형 변수가 정규분포를 따른다고 가정하거나 실제로 정규분포를 따르는 경우가 많기 때문~’
--187페이지에서--
.
‘ #부트스트랩 = 데이터가 아무리 작거나 이상하더라도 강건한 결론을 도출할 수 있습니다’
--195페이지에서--
.
‘비즈니스에대한 이해와 지식이 없는 상태라면 어떤 방법을 TJㅗ 의미 있는 실험을 수행할 수 없습니다’
--228페이지에서--
.
‘무엇을 테스트해야하는지 아는 것이 최우선입니다. 무엇을 달성하려고 하는지를 명확하게 인지하지 못한 상태에서 실험을 진행하면 실험에 실패하기 마련입니다’
--229페이지에서--
.
‘실험의 목표는 좋은 비즈니스 결정을 내리는 것입니다. 수익에만 매달리면 비즈니스를 개선할 수 있는 많은 가능성을 놓칠 수 있습니다.’
--231페이지에서--
.
‘비즈니스파트너는 종종 광범위하고 명확한 답을 원하고 세부 사항을 길게 나열하는 것을 좋아하지 않습니다.’
--233페이지에서--
.
‘명확한 행동논리의 장점 두가지
1.행동 논리는 그 자체로 실험 가능합니다
2.일반적으로 잠재적인 이점을 제공한다는 것~‘
--234~235페이지에서--
.
‘ #알버트아인슈타인 = 문제를 풀 시간이 한 시간이 주어진다면 나는 문제에 대해 생각하는데 55분을 쓰고 나머지 5분동안 문제를 푸는 방법을 생각할 것이다라고 (중략) 즉 논리를 충분히 이해하는 것이 가장 중요~’
--235페이지에서--
.
‘논리를 명확하게 설명하려면 비즈니스 지표를 작은 구성 요소 단위로 세분화하는 것이 좋습니다.’
--236페이지에서--
.
#책을덮으면서
95페이지보면서~ 행동데이터, 사람이 어떻게 행동하는가에 따라서 기업이 그들의 목적을 이루기위해 분석한대로 지향점을 현실에 반영하는 것.. 책에서도 자주 등장하는것처럼 CCTV가 사람의 행동을 분석해서, 그 안테나샵에서 벌어지는 시사점을 기업에 전달해주는 행동데이터의 분야도 커진다고 하던데~ 결국 소비자의 그 무엇이든 데이터를 분석해서 인사이트를 얻는 그 과정이 매우 중요함을 이책에서 다시한번 느끼게된다. (물론 저자의 말대로 겉으로 드러나는 것 밖에는 분석을 못하지만 말이다)
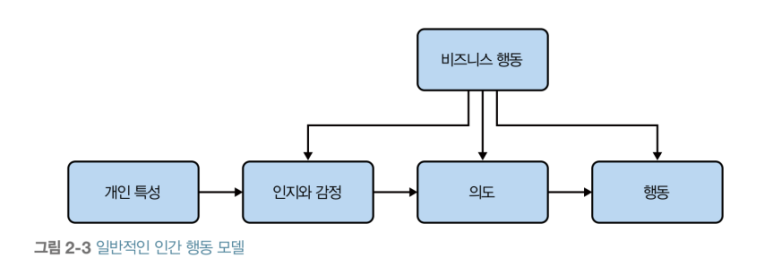
124페이지보면서~ 보여지는 고객의 행동을 수집하고 분석해서, 유의미한 그 뭔가를 도출해내기위해서는 참 다양하고 복잡한 사전 로직을 구성하고, 상호 연계되는 부분까지 고려한 세심한 디테일 부분이 살아있어야한다는 것을 저자는 보여주고 있다 (프로그램을 잘 다루지는 못하지만, 순서도, 로직, 다이어그램, 연관관계 등에 대한 설명을 하는 표,서식을 볼 때, 참 세밀한 것까지 다루고 사전에 고민하는 것을 충분히 알 수 있게 되어있다)
호기심을 가지고, 또한 개선이 이루어져야한다는 문제의식을 가지고, 수시로 고객에 대한 데이터를 모아두고 정리해야하는 것을 두려워해서는 안될거같아보인다. 그 데이터, 그리고 그 호기심이 파이선, R과 같은 프로그램과 만나면 정말 어마무시한 데이터를, 분석의 결과를 도출해낼 수 있음을 이책을 통해서 배운다. 늘 뭔가 지금보다는 나아지기를 바라는 생각으로 현재를 바라봐야할거같다. 좋은 내용이다 (물론 능숙하게 프로그램을 다루지도 못하고, 프로그램과 관련된 세부 사항은 잘 이해하기가 어렵지만, 그럼에도 불구하고 논리적인 접근에 대해서는 프로그래머가 참 멋진 생각을 담고 있는 직업이구나 하는 생각을 해본다)
멋진 책이다.