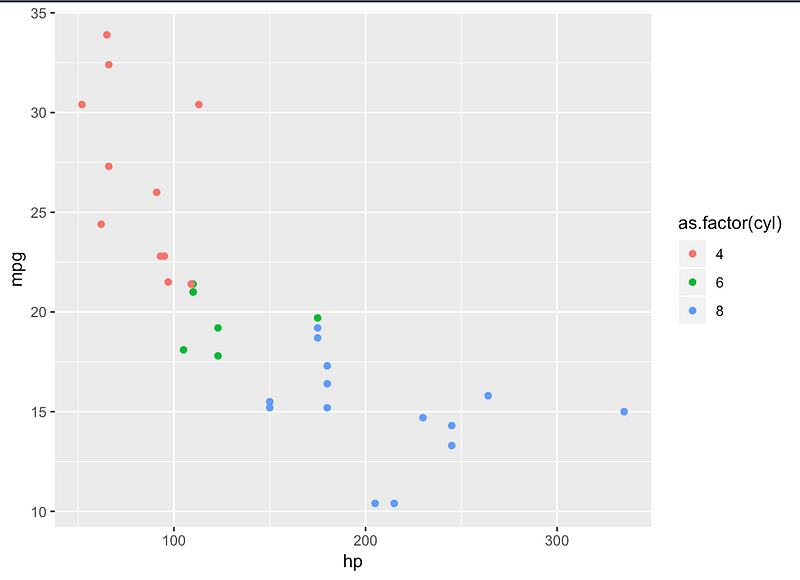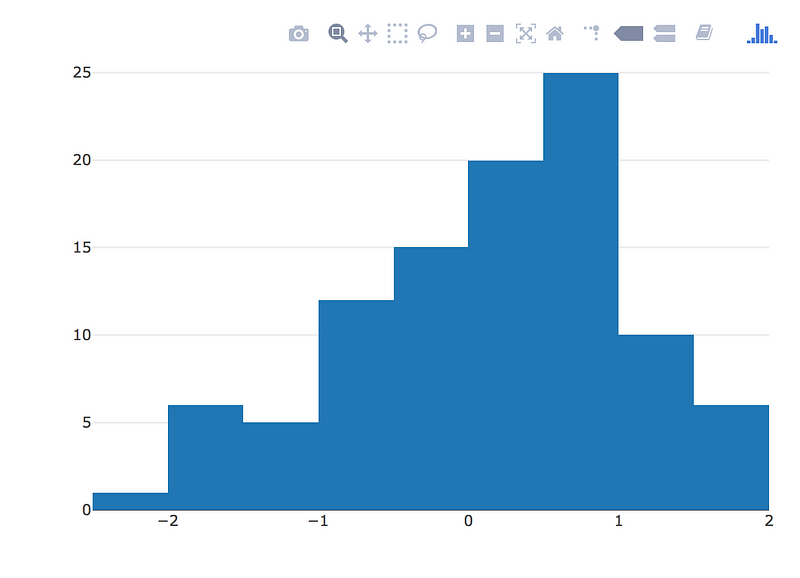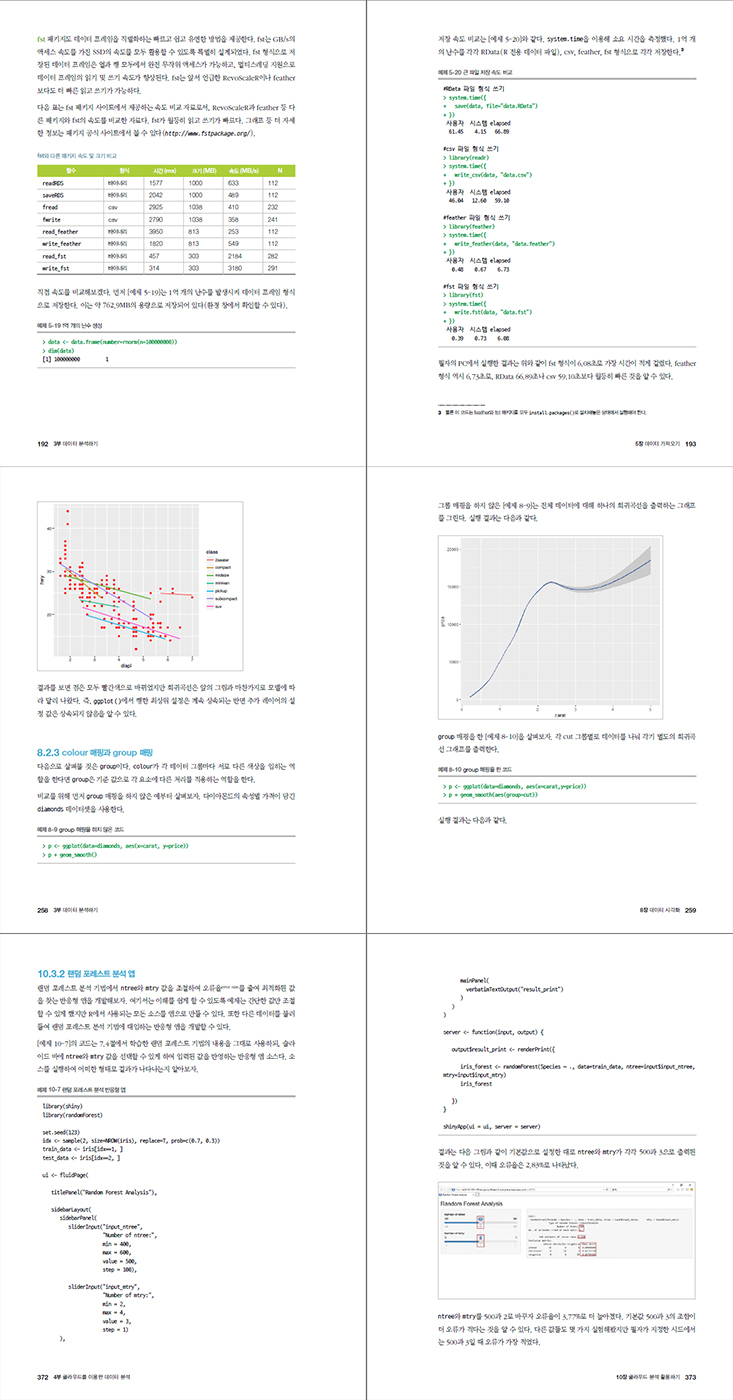

R을 공부하는 학생들은 어떻게 R을 시작해야하는지 당황해 하는 경우가 종종 있습니다. 이 책은 R을 활용하는데 기본이 되는 사항들을 알차게 잘 정리하고 있는 책으로, R 스튜디오 설치, R 기본 문법 그리고 데이터를 분석하고 시각화 하는 방법에 대해서 전반적으로 다루고 있습니다. 특히 다른 새로운 점은 AWS 클라우드를 통해서 분석하는 방법을 기술하고 있는데, 클라우드 분석을 통해서, 네트워크 속도나 하드웨어 스팩을 좀 더 유연성있게 사용할 수 있는 방안을 소개합니다.

[기존 R 도서와의 차별성]
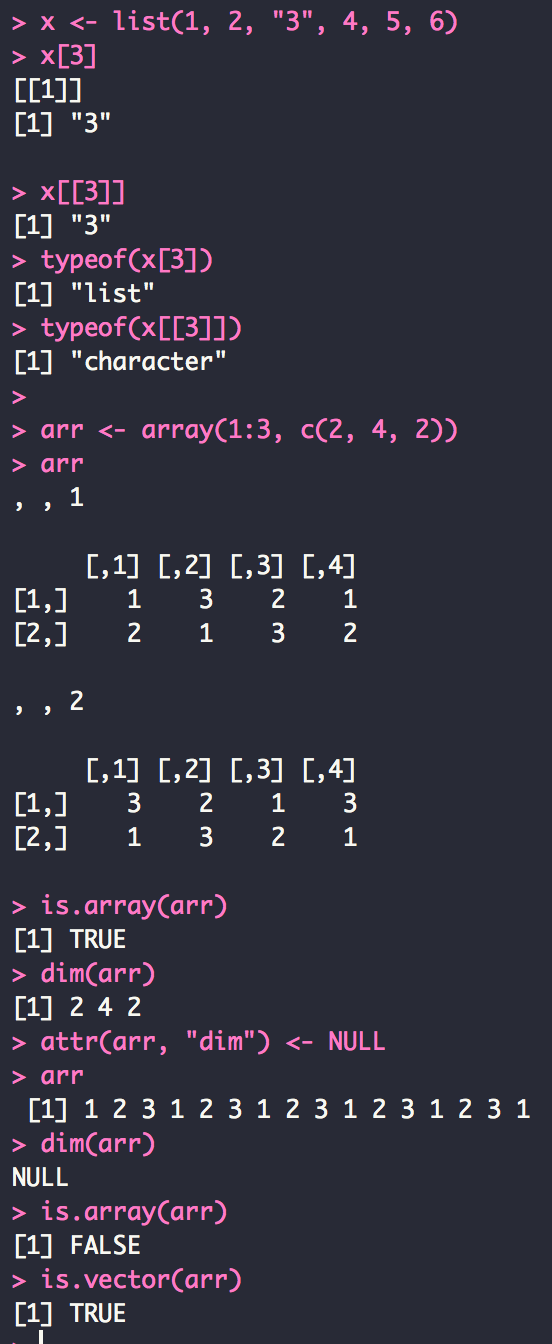
기존의 R 도서의 경우 문법을 중심으로 하는 책들이 상당히 많습니다. 그러나 R을 실제 이용하려할 때 굉장히 걸리는 부분이, 기본적으로 이용해야하는 사항들에 대해서 체계적으로 구성을 하고 있지 않다는 점이죠. 즉 R을 공부할 때는 반드시 통계, 시각화 등 기초적으로 알아야 하는 사항들이 매우 많습니다.
이 책은 이러한 점을 고려한 부분이 있습니다. 기본적으로, 사용하는 방법에 충실하게 내용을 구성했고, 예제를 설명함에 있어서도, 그에 대한 사항을 이해하기 쉽게 찬찬히 설명하고 있습니다. 즉 현업에서 기본적으로 데이터 분석을 할 때 필요한 사항들을 R을 통해 처리하고, 분석할 수 있도록 그 과정을 단계별로 충실히 설명합니다.
[데이터를 처리하는 기술]
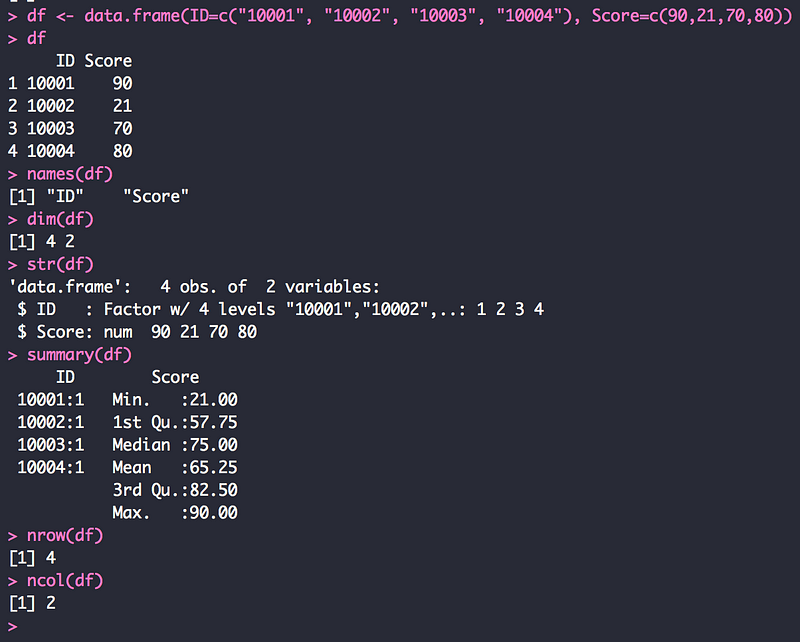
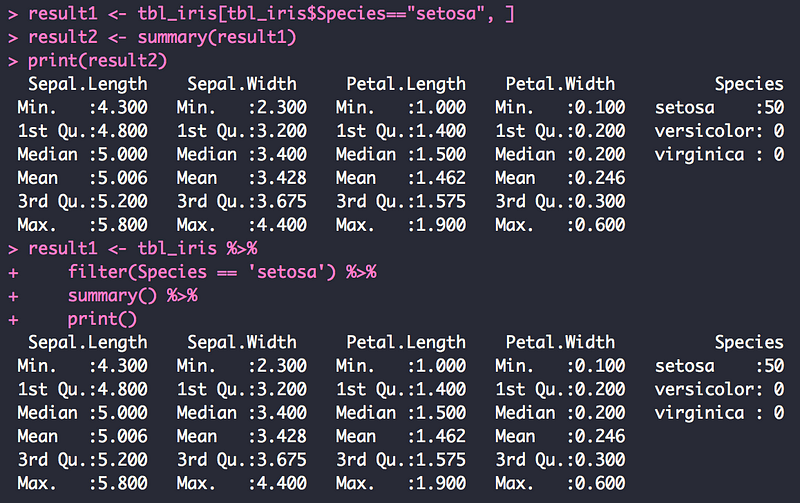
특히 이 책에서는 데이터를 분석할 때 현장에서 주로 하게 되는 데이터를 정비에 대해서 언급을 하고 있습니다. 이 점은 이 책에 큰 특징으로, 데이터 정비를 다루는 방법에서 R에서 이용하면 좋을 패키지를 소개하고 있습니다. 특히 Dplyr과 tidyr은 이용하는 방법이 RDBMS의 SQL 쿼리와 사용하는 방법이 매우 유사하기 때문에, 실제 이를 이용하면, 매우 간단하게 데이터를 처리할 하나의 중요한 팁을 배울 수 있습니다.

인상깊었던 것]
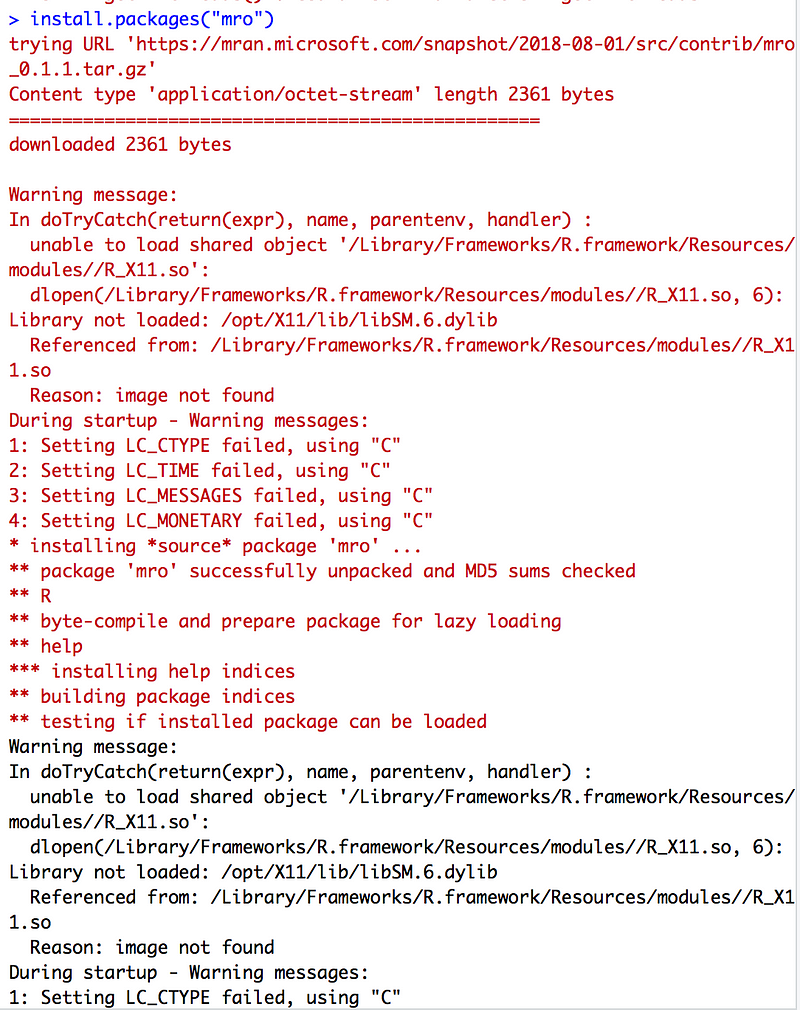
MRO(Microsoft R Open) - 이 책에서는 마이크로소프트웨어에서 멀티 스레드를 지원하기 위해서 R를 수정해서 배포하는 것을 소개했는데, 저의 경우 사실 멀티 쓰레드가 안되서 굉장히 고생한 적이 있었는데, 이 책에서 간단하게 이를 소개해 준 점은 참 좋았습니다.

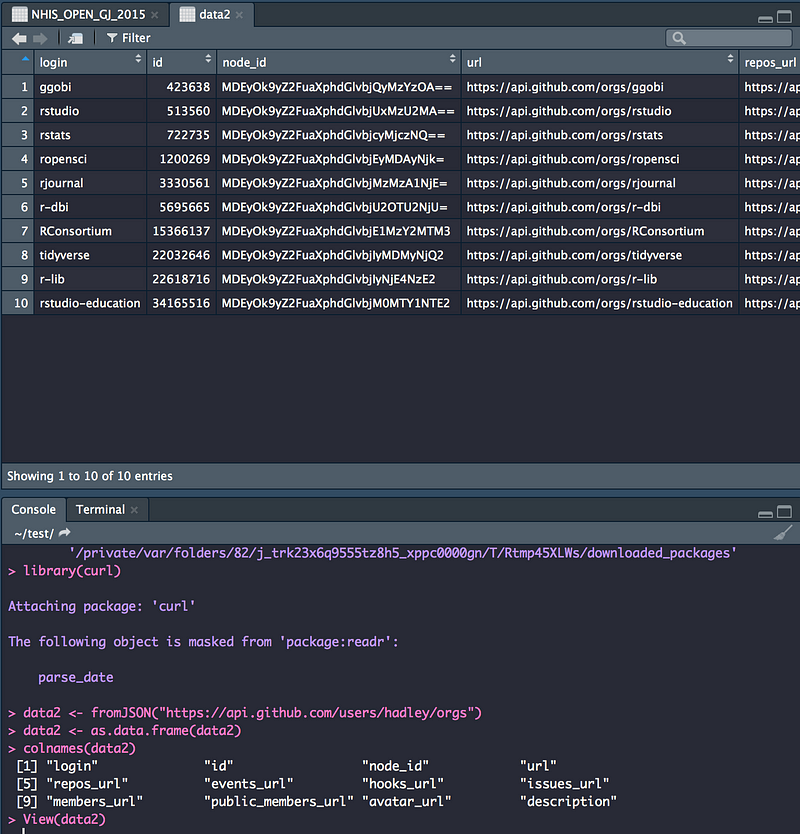
또한 이 책에서는 데이터를 수집하는 장소, 국내 공공데이터 포털과 서울열린데이터광장에 대한 소개를 통해, 독자가 사용하고 싶은 데이터를 어디서 얻으면 되는지와 이를 R을 통해 어떻게 수집하는 지를 소개하고 있스니다. 이 점은 기존의 R 책에서는 소개가 잘 안되더 사항인데, 실무에서 이용할 때 참고 하면 정말 좋을 것 같습니다.

R을 공부하다보면, 문법에 지치거나, 알고리즘에 지치는 경우가 많습니다. 처음 시작을 할 때, 실무에는 바로 쓰고 싶은데, 공부를 하자니 너무 막막한 경우가 많습니다. 이 책의 경우에는 실제 필요한 부분만을 잘 정리해서, R을 이용하는 방법에 대해서 소개하고 있습니다. 처음에 입문과정에서, "아 R을 이렇게 이용하는 구나" 하는 점에서 접근하면 좋을 것 같고, 이후 R에 대해서 구체적인 기본서 등을 참고하면서 실력을 늘려가는 방법도 좋을 것 같습니다.